一键巡检
概述
一键巡检:对云平台关键资源和服务进行全方位一键式健康检查,并根据巡检结果为巡检资源和服务进行健康评分,同时提供巡检建议和巡检报告,助力高效运维,确保云平台资源和服务处于最佳状态。一键巡检适用于需要对云平台进行集中高效运维场景。
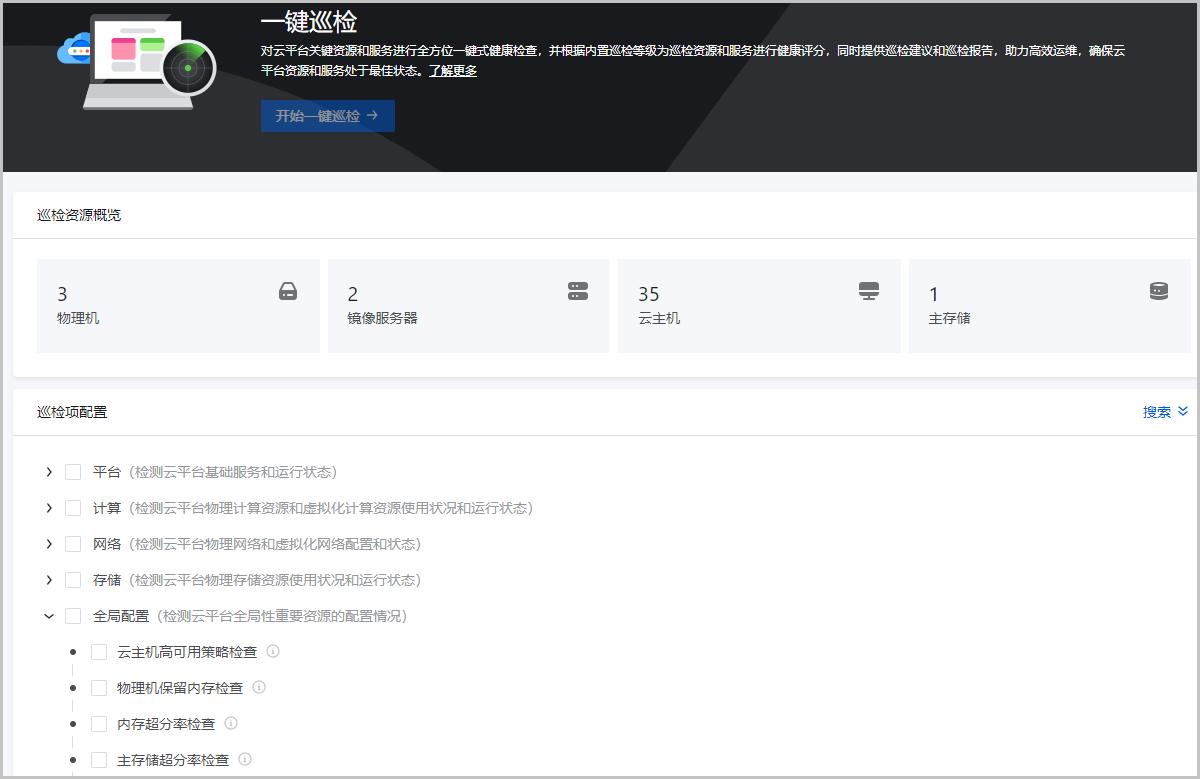
功能原理
- 巡检类别和巡检项:一键巡检提供平台、计算、网络、存储、全局设置五大类别巡检项,支持对管理节点、物理机和云主机、镜像服务器和主存储、物理/虚拟网络和网卡、许可证等云平台关键资源和服务进行巡检:
- 平台:检测云平台基础服务和运行状态。
- 计算:检测云平台物理计算资源和虚拟化计算资源使用状况和运行状态。
- 网络:检测云平台物理网络和虚拟化网络配置和状态。
- 存储:检测云平台物理存储资源使用状况和运行状态。
- 全局设置:检测云平台全局性重要资源的配置情况。
用户可自定义根据类别选择巡检项进行一键巡检,启动巡检后,云平台将对所选择的巡检项涉及的资源或服务进行健康检查。详细巡检项信息可参考巡检项总览。
- 巡检结果:一键巡检针对所巡检的资源或服务提供四种巡检结果,分别为正常、警告、故障和失败。
- 正常:所巡检的资源或服务处于正常状态,通过绿色图标标识。
- 警告:所巡检的资源或服务状态欠佳,可能会在一定程度上影响相关资源和服务的性能和稳定性,通过黄色图标标识。
- 故障:所巡检的资源或服务状态非常危险,可能会严重影响业务的运行,通过红色图标标识。
- 失败:资源或服务巡检失败,可能会严重影响业务的运行,通过灰色图标标识。
- 健康评分:
一键巡检内置健康评分机制,支持对所巡检的资源或服务的健康状态进行量化评分,帮助用户直观准确把握云平台整体运行状态。
巡检资源/服务评分:根据资源或服务的巡检结果进行评分。- 若某资源/服务所有巡检属性均正常,该资源/服务的巡检结果为正常,评分为100分。
- 若某资源/服务存在一个巡检属性处于警告状态,其他巡检属性均正常,该资源/服务的巡检结果为警告,评分为50分。
- 若某资源/服务存在一个巡检属性处于故障或失败状态,该资源/服务的巡检结果为故障或失败,评分为0分。
巡检项评分:根据巡检项所涉及资源或服务的评分进行统计。-
若巡检项非全局设置类别,该巡检项按照如下机制进行评分:
- 评分机制:(资源1评分 + 资源2评分 + …… + 资源N评分)/(N*100)*100。
- 例子:假设某巡检项下涉及3个资源,巡检结果分别为正常、警告、故障/失败,对应的资源评分为100、50、0,则该巡检项的评分为:(100 + 50 + 0)/(3*100)*100=50分。
-
若巡检项为全局设置类别,该巡检项按照如下机制进行评分:
- 评分机制:根据该巡检项所涉条目对应的分数,评为该巡检项的健康检查分数。
- 例子:假设某巡检项下所涉条目,巡检结果为警告,对应的条目评分为50,则该巡检项的评分为50分。
云平台整体评分:根据各个巡检项所得评分按照如下评分机制进行综合统计:- 评分机制:(巡检项1评分 + 巡检项2评分 + …… + 巡检项N评分)/(N*100)*100。
- 例子:假设用户共选择3个巡检项进行一键巡检,对应的评分为100、50、0,则云平台总体评分为:(100 + 50 + 0)/(3*100)*100=50分。
- 巡检建议:
一键巡检针对警告和故障状态的巡检资源和服务,分析其面临的潜在风险以及对相关资源和服务的影响,并提供针对性的修复建议。详细巡检建议信息可参考巡检项总览。
- 巡检报告:
一键巡检支持导出PDF格式的巡检报告,汇总展示巡检所涉平台配置信息、资源状态统计信息以及巡检项结果统计信息。此外,巡检报告汇总所有异常巡检项详情,并为每条异常巡检项提供巡检建议。
功能优势
- 全方位高效自定义巡检:五大类巡检项涵盖云平台上所有关键资源和服务,支持自定义选择巡检,分钟级交付。
- 多级评分机制:内置资源/服务、巡检项、云平台三级评分机制,助力用户从微观至宏观掌控云平台运行状态。
- 智能风险排查建议:智能推送资源级风险分析和应对措施,助力精准高效运维。
管理一键巡检
在ZStack Cloud主菜单,点击,进入一键巡检界面。
| 操作 | 描述 | 巡检状态 |
|---|---|---|
| 开始一键巡检 | 自定义选择巡检项后,对所选巡检项进行一键巡检。 | / |
| 暂停一键巡检 | 暂停对所选巡检项进行一键巡检。 | 巡检中 |
| 继续一键巡检 | 恢复对所选巡检项进行一键巡检。 | 巡检暂停 |
| 取消一键巡检 | 取消对所选巡检项进行一键巡检。 | 巡检中 |
| 重新巡检 | 对上次一键巡检所选巡检项进行重新检查。 | 巡检完成 |
| 导出巡检报告 | 导出PDF格式的巡检报告。 | 巡检完成 |
查看巡检结果
在ZStack Cloud主菜单,点击,进入一键巡检界面。选择需进行巡检的条目后,点击开始一键巡检。完成巡检后,可查看巡检结果。
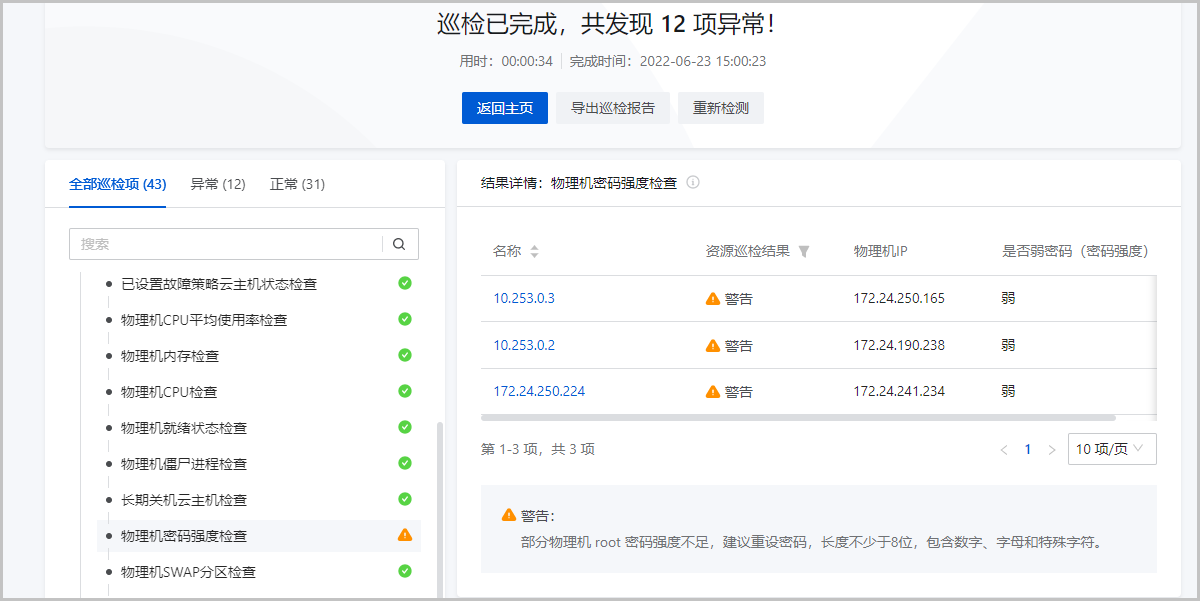
巡检结果通过分数量化的方式展示所选巡检项整体健康运行状态,并将所选巡检项根据状态进行分类汇总,方便用户快速查找状态异常的巡检项。同时通过列表形式清晰展示各个巡检项涉及资源的信息和状态,并提供相应的巡检建议。
整体健康检查结果
巡检结果页面上半栏汇总统计本次所有巡检项数量以及处于异常状态的巡检项数量,并根据健康评分机制为本次巡检项进行整体统计打分,直观展示巡检项整体健康状态。同时,巡检结果记录本次一键巡检的用时以及完成时间,方便用户安排下次巡检时间。若需了解详细健康评分机制,可参考健康评分。
巡检项状态分类展示
- 若巡检项所涉所有资源/服务的巡检结果均为正常,则该巡检项通过绿色图标标识,归类为正常。
- 若巡检项所涉所有资源/服务的巡检结果为警告,或部分资源/服务的巡检结果为警告、其余为正常,则该巡检项通过黄色图标标识,归类为异常。
- 若巡检项所涉所有资源/服务的巡检结果为故障,或部分资源/服务的巡检结果为故障、其余为正常或警告,则该巡检项通过红色图标标识,归类为异常。
- 若巡检项所涉所有资源/服务的巡检结果为失败,或部分资源/服务的巡检结果为失败、其余为正常、警告或故障,则该巡检项通过灰色图标标识,归类为异常。
巡检资源信息状态和巡检建议
- 列表信息:
- 基本信息:一键巡检为不同的巡检资源和服务展示不同的基本信息,例如巡检项镜像服务器就绪状态检查展示云平台镜像服务器名称、类型、和就绪状态。
- 巡检结果:根据巡检资源和服务的健康状态展示相应的巡检结果,包括正常、警告、故障、失败。
- 正常:所巡检的资源或服务处于正常状态,通过绿色图标标识。
- 警告:所巡检的资源或服务状态欠佳,可能会在一定程度上影响相关资源和服务的性能和稳定性,但不会严重影响业务的运行,通过黄色图标标识。
- 故障:所巡检的资源或服务状态非常危险,可能会严重影响业务的运行,通过红色图标标识。
- 失败:无法对资源或服务进行巡检,通过灰色图标标识。
- 巡检建议:一键巡检针对警告和故障状态的巡检资源和服务,分析其面临的潜在风险以及对相关资源和服务的影响,并提供针对性的修复建议,助力用户高效运维。详细巡检建议信息可参考巡检项总览。
巡检项总览
| 巡检类型 | 巡检项 | 巡检项含义 | 巡检建议 |
|---|---|---|---|
| 平台 | 许可证过期检查 | 检查云平台许可证、模块许可证许可证是否过期。 | 若检测到云平台相关许可证服务即将到期或已到期,为不影响您的正常使用,请尽快联系平台相关人员进行授权更新,以继续使用本平台功能。 |
| 物理机时间源一致性检查 | 检查物理机是否设置时间源同步以及物理机时间源设置是否与集群内其他物理机一致。 | 若检测到物理机时间源与集群内其他物理机时间源不一致或物理机系统时钟未与时间源同步,请SSH登录对应物理机系统,检查时间源配置。 | |
| 监控数据容量检查 | 检查云平台监控数据管理节点所在磁盘的容量占比。 | 若检测到云平台监控数据容量已占用管理节点所在磁盘超过50%的容量,请在云平台的全局设置中调整监控数据保留大小或监控数据保留周期。 | |
| 管理节点系统盘已用容量检查 | 检查云平台管理节点系统盘使用率和使用量。 | 若检测到云平台管理节点系统盘使用率已超过70%甚至90%,请立即SSH登录至管理节点系统,检查并清理对业务无影响的数据。 | |
| 管理节点数据库备份任务检查 | 检查云平台管理节点数据库是否配置异地备份任务以及异地备份任务配置是否生效。 |
若检测到云平台管理节点未配置数据库异地备份,请SSH登录至管理节点系统,检查是否配置crontab定时任务。 若检测到云平台管理节点数据库异地备份配置未生效,请SSH登录至管理节点系统,检查管理节点是否可以免密登录至指定的备份节点。 |
|
| 管理节点高可用状态检查 | 检查云平台管理节点是否配置高可用或高可用服务是否正常。 |
若检测到云平台管理节点未配置高可用服务,为确保云平台高可用,建议立即进行配置。 若检测到云平台管理节点高可用服务状态异常,请立即确认管理节点系统状态。 |
|
| 灾备服务器容量检查 | 检查云平台上本地备份服务器和远端备份服务器的容量使用率。 |
若检测到灾备服务器容量使用率不低于70%且不高于90%,请及时删除过期灾备数据或扩容灾备服务器容量。 若检测到灾备服务器容量使用率不低于90%,可能会导致灾备任务无法执行,请及时删除过期灾备数据或扩容灾备服务器容量。 |
|
| 计算 | 物理机CPU检查 | 检查云平台上物理机每个CPU的状态和温度。 |
若检测到物理机的CPU温度已连续5分钟不低于80℃,温度持续过高可能会导致物理机运行不稳定、物理机自动下电或重启,中断云主机业务。请依次检查以下几项:
若检测到物理机CPU处于离线状态,可能会导致物理机运行不稳定、中断云主机业务。请在物理机带外管理界面检查是否存在CPU、主板故障告警。 |
| 物理机内存检查 | 检查云平台上物理机内存使用率、交换分区使用率、以及是否存在ECC告警。 | 若检测到物理机的内存处于警告状态,可能会导致物理机OOM内存溢出、影响物理机性能、中断云主机业务。可参考以下建议逐一排查:
|
|
| 物理机CPU平均使用率检查 | 检查云平台上物理机CPU平均使用率。 |
若检测到物理机CPU平均使用率超过70%,请登录物理机系统,确认物理机上是否存在异常进程。若未存在异常进程,建议考虑对集群进行扩容。 若检测到物理机CPU平均使用率超过90%,请登录物理机系统,确认物理机上是否存在异常进程。若未存在异常进程,建议立即对集群进行扩容。 |
|
| 物理机系统盘已用容量检查 | 检查云平台上物理机系统盘使用率和使用量。 | 若检测到物理机系统盘容量使用率超过70%甚至90%,请立即登录至物理机系统,检查并清理对业务无影响的数据。 | |
| 物理机上云主机数量检查 | 检查物理机上运行云主机的数量。 | 若检测到物理机上运行云主机已超20个,请确认物理机资源使用情况,按需热迁移云主机,确保均衡使用物理机资源。 | |
| 物理机就绪状态检查 | 检查云平台上物理机是否失联。 | 若检测到云平台物理机失联,请立即检查相关物理机系统状态是否正常。 | |
| 物理机系统密码强度检查 | 检查云平台上物理机root密码强度是否满足要求。 | 若检测到物理机root密码强度不足,建议重设密码,长度不少于8位,包含数字、大小写字母和特殊字符。 | |
| 物理机SWAP分区检查 | 检查云平台上物理机SWAP分区是否关闭。 |
若检测到物理机未关闭SWAP分区,可能会影响云主机业务,建议按需登录对应物理机系统关闭SWAP分区。 若检测到云平台存在分布式存储,物理机未关闭SWAP分区,可能会严重影响云主机业务,请立即登录对应物理机系统关闭SWAP分区。 |
|
| 物理机僵尸进程检查 | 检查物理机上运行的僵尸进程数量。 | 若检测到物理机上存在僵尸进程,可能是由于云主机进程或其他系统服务进程未正常退出。该情况可能会导致云主机无法正常启动或物理机失联。请检查相关物理机僵尸进程具体对应的服务,可将云主机迁移至其他物理机,重启该物理机解决。 | |
| 高可用云主机运行状态检查 | 检查云平台上已启动高可用的云主机运行状态。 | 若检测到已开启高可用的云主机处于非运行状态,请查看对应云主机运行状态是否正常。 | |
| 云主机CPU平均使用率检查 | 检查云平台上云主机CPU平均使用率。 | 若检测到云主机CPU平均使用率已超80%甚至95%,请立即登录至对应云主机系统内检查,确认是否存在异常业务,并按需优化运行业务或升配云主机计算规格。 | |
| 云主机系统盘已用容量检查 | 检查云平台上云主机系统盘(非厚置备系统盘)使用率。 | 若检测到云主机系统盘(非厚置备系统盘)容量使用率已超过70%甚至90%,请立即登录至对应云主机系统,检查并清理对业务无影响的数据,或按需对云主机系统盘进行扩容。 | |
| 已设置故障策略云主机状态检查 | 检查云平台上已开启故障检测功能的云主机是否出现故障。 | 若检测到云主机处于故障状态,请检查对应云主机系统状态是否正常。 | |
| 长期关机云主机检查 | 检查云平台上关机天数不低于30天的云主机。 |
若检测到云主机处于关机状态已不少于30天,请检查相关云主机是否为运行业务的云主机。若不是可清理释放资源。 |
|
| 网络 | 物理机网卡检查 | 检查物理机的网卡状态、连接模式、丢包率、速率、以及是否处于全双工模式。 |
若检测到物理机的网卡处于警告状态,可能会导致物理机失联,云主机业务网络通信受影响。可参考以下建议逐一排查:
若检测到物理机的网卡处于故障状态,可能会导致云主机业务网络通信或IO读写受影响,可参考以下建议逐一排查:
|
| 物理机Bond内物理网口状态检查 | 检查云平台上物理机Bond内物理网口状态是否UP。 | 若检测到Bond内物理机网口状态为DOWN,请检查物理机网卡是否存在故障。 | |
| 业务网络冗余性检查 | 检查云平台上业务网络对应物理网口是否配置Bond。 | 若检测到云平台业务网络使用的物理网口未配置Bond,不具备网络冗余性,请按需确认是否需配置Bond。 | |
| 物理机管理网连通性检查 | 检查云平台上物理机管理网络IP之间是否连通。 | 若检测到物理机管理网络IP之间无法连接,请检查物理机系统状态是否正常。 | |
| 物理机管理网丢包检查 | 检查到云平台上物理机管理网络IP是否存在丢包。 |
若检测到物理机管理网络IP丢包,请检查对应物理机的物理链路是否正常以及物理网卡是否存在硬件故障。 若检测到物理机管理网络IP网络不通,丢包率为100%,请检查对应物理机系统状态是否正常。 |
|
| 物理机存储网丢包检查 | 检查到云平台上物理机存储网络IP是否存在丢包。 |
若检测到物理机存储网络IP丢包,请检查对应物理机的物理链路是否正常以及物理网卡是否存在硬件故障。 若检测到物理机存储网络IP网络不通,丢包率为100%,请检查对应物理机系统状态是否正常。 |
|
| 存储 | 物理机HDD检查 | 检查云平台上物理机HDD磁盘健康状态、IO利用率、以及是否存在坏道。 |
若检测到物理机的HDD盘处于警告状态,可能会导致业务云主机IO读写卡顿,影响云主机业务。可参考以下建议逐一排查:
|
| 物理机SSD检查 | 检查云平台上物理机SSD磁盘健康状态、IO利用率、剩余寿命、以及温度。 |
若检测到物理机的SSD盘处于警告状态,可参考以下建议逐一排查:
若检测到物理机的SSD盘处于故障状态,可参考以下建议逐一排查:
|
|
| 物理机RAID卡检查 | 检查云平台上物理机RAID卡状态以及缓存模式。 |
若检测到RAID 处于降级状态:该情况可能影响数据冗余功能,请检查RAID 卡健康状态并及时处理。 若检测到物理机RAID卡的缓存模式非write-through,该情况可能会导致存储服务无法启动,断电后系统盘数据无法恢复。请将Raid卡缓存模式调整为write-through。 若检测到物理机RAID卡出现异常,可能是由于RAID卡硬件故障或RAID接触不良。该情况可能会导致物理机系统挂死,业务云主机IO无法读写。请检查相关物理机RAID卡健康状态,并物理机带外管理检查是否存在RAID故障告警,若存在故障告警须及时更换。 |
|
| 云盘快照数量检查 | 检查云盘上创建的快照数量。 | 若检测到云盘快照数量已超过20个,过多快照会影响云主机性能、数据安全以及主存储容量,请按需清理云盘上对业务无影响的快照数据。 | |
| 主存储就绪状态检查 | 检查云平台上主存储是否存在失联。 | 若检测到主存储失联,请立即检查相关主存储状态是否正常。 | |
| 镜像服务器就绪状态检查 | 检查云平台上镜像服务器是否存在失联。 | 若检测到镜像服务器失联,请立即检查相关镜像服务器存储状态是否异常。 | |
| 镜像服务器已使用容量检查 | 检查云平台上镜像服务器使用率和使用量。 |
若检测到镜像服务器已用物理容量超过70%,建议对镜像服务器存储进行扩容。 若检测到镜像服务器已用物理容量超过85%,请清理无用镜像资源,释放镜像服务器空间,并考立即对镜像服务器存储进行扩容。 |
|
| 主存储已用物理容量检查 | 检查云平台上主存储使用率和使用量。 |
若检测到主存储已用物理容量超过70%,建议对主存储进行扩容。 若检测到主存储已用物理容量超过85%,为避免存储空间被写满,请清理无用的云主机/云盘资源,释放主存储空间,并立即对主存储进行扩容。 |
|
| 分布式存储Mon节点状态检查 | 检查云平台上分布式存储Mon节点的连接状态是否正常。 | 若检测到分布式存储Mon节点失联,请立即检查分布式存储状态是否正常。 | |
| 分布式存储状态检查 | 检查云平台上分布式存储健康状态是否正常。 | 若检测到分布式存储健康状态异常,请立即登录物理机系统,检查分布式存储系统状态。 | |
| 主存储心跳网络检查 | 检查云平台上主存储的存储心跳网络配置是否正确。 | 若检测到主存储未配置存储心跳网络,请立即检查并配置主存储的存储心跳网络,确保实时监控主存储健康状态。 | |
| 全局设置 | 云主机高可用策略检查 | 检查云平台全局设置中云主机高可用策略是否为激进策略。 | 若检测到云主机高可用策略为保守策略,将不支持云主机高可用。为保证云主机上业务高可用,请在平台设置中将该设置调整为激进策略。 |
| 物理机保留内存检查 | 检查云平台全局设置中物理机保留内存设置是否合理。 | 若检测到物理机保留内存较小,由于云平台系统服务会占用一定物理机内存,为保证系统服务正常运行,请在全局设置中调整物理机保留内存至少为30G。 | |
| 内存超分率检查 | 检查云平台全局设置中物理机内存超分率设置是否合理。 | 若检测到物理机内存超分率高于1,由于内存超分存在物理机OOM内存溢出风险,生产环境不建议内存超分。请在全局设置中调整内存超分率为1。 | |
| 主存储超分率检查 | 检查云平台全局设置中主存储超分率设置是否合理。 | 若检测到主存储超分率高于1,由于主存储超分存在存储池溢出风险,生产环境不建议主存储超分。请在全局设置中调整主存储超分率为1。 | |
| 主存储使用阈值检查 | 检查云平台全局设置中主存储使用阈值设置是否合理。 | 若检测到主存储使用阈值设置偏高,为防止系统过度使用主存储空间,请在全局设置中调整主存储使用阈值为0.85。 | |
| 主存储保留容量检查 | 检查云平台全局设置中主存储保留容量设置是否合理。 | 若检测到主存储保留容量较少,请在全局设置中调整主存储保留容量为200G。 | |
| 镜像服务器保留容量检查 | 检查云平台全局设置中镜像服务器保留容量设置是否合理。 | 若检测到镜像服务器保留容量较少,请在全局设置中调整镜像服务器保留容量为200G。 |