网络虚拟化
概述
网络虚拟化是一种脱离专用网络硬件抽象出的虚拟网络技术,底层硬件仅需提供基础的数据包转发服务。网络虚拟化可提供多种网络服务,包括数据交换、路由、安全组和防火墙等,使网络体验同物理网络一样。
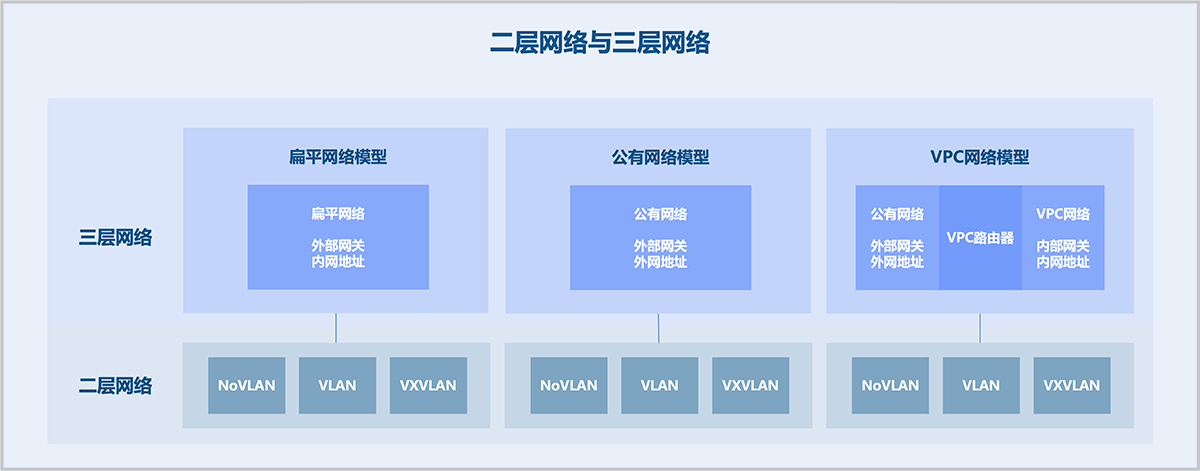
云平台将网络模型抽象为二层网络与三层网络,二层网络对应于二层广播域,提供一种二层隔离方式,三层网络主要与OSI七层模型中第4层~第7层网络服务相对应。提供二层隔离技术的NoVLAN、VLAN、VXLAN、SDN等均可作为二层网络。创建二层网络,相当于在二层网络所挂载的集群内所有物理机上,创建对应的虚拟交换机来提供广播域。在二层网络之上,创建的三层网络类型包括:扁平网络、公有网络、VPC网络。基于三层网络可提供各种网络服务,包括:DHCP、DNS、弹性IP、端口转发、负载均衡等。
技术特性
三层网络
三层网络包括:扁平网络、公有网络、VPC网络。
扁平网络可给云主机分配私有网络地址,同时云主机可通过分布式弹性IP访问公有网络。扁平网络支持DHCP、User Data、安全组、弹性IP、端口镜像等网络服务。
VPC网络是一块可由租户自定义的网络空间,其目的是让租户在云平台上构建出一个隔离的、可自行管理配置及策略的虚拟网络环境,从而进一步提升租户在云环境中的资源安全性。VPC网络和服务由VPC路由器提供,一个VPC路由器下可提供多个相互隔离的VPC网络,给云主机提供DHCP、DNS、SNAT、路由表、安全组、VPC防火墙、弹性IP、端口转发、负载均衡、IPsec、Netflow、OSPF(动态路由)、组播路由等网络服务。
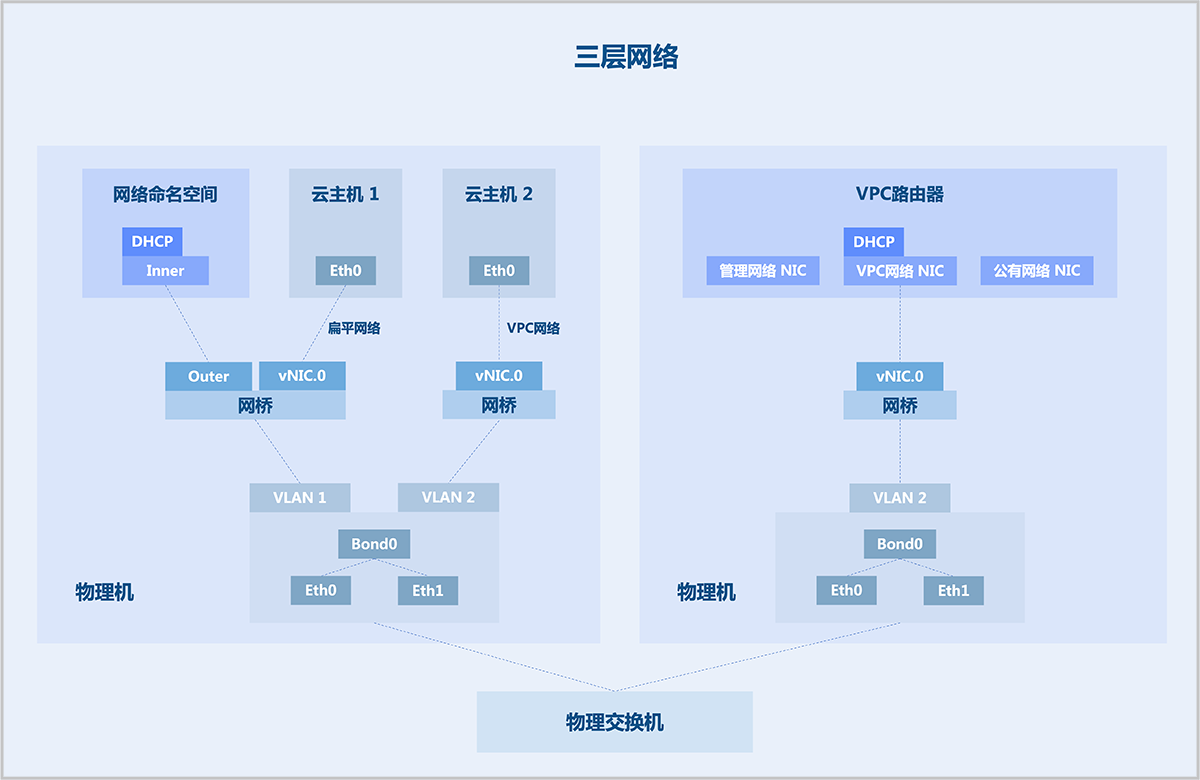
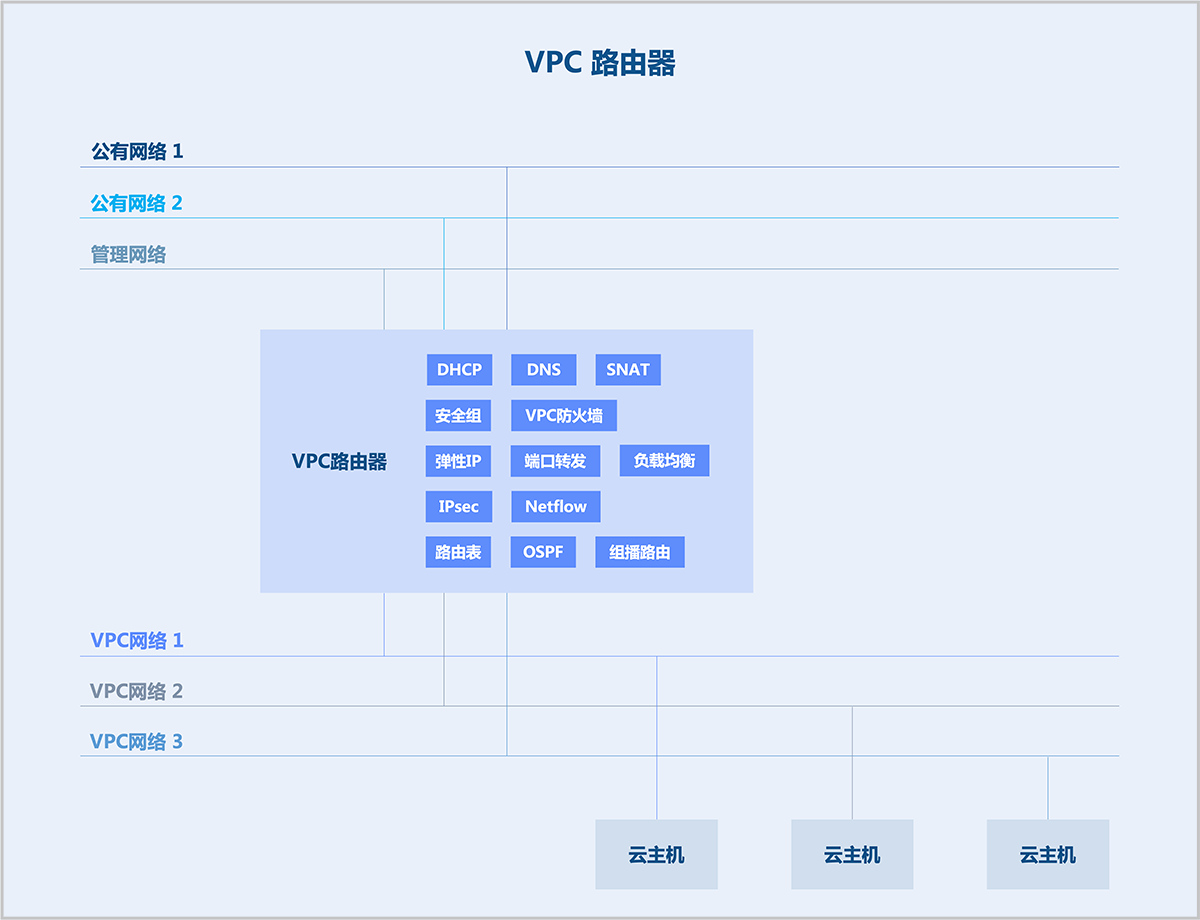
VPC路由器
VPC路由器是一种专用云主机,运行定制的Linux操作系统,以及管理服务代理程序。一个VPC路由器下可提供多个相互隔离的VPC网络。每个VPC路由器中包含一个管理服务代理程序,通过HTTP协议接收来自管理节点的命令以配置网络服务,可为云主机提供DHCP、DNS、SNAT、路由表、安全组、VPC防火墙、弹性IP、端口转发、负载均衡、IPsec、Netflow、OSPF(动态路由)、组播路由等网络服务。
安全组
在传统数据中心,网络可分为:信任区域、DMZ区域、非信任区域,通过边界防火墙进行流量控制,保障网络安全。在虚拟化数据中心,边界防火墙可能力不从心,例如:不同租户之间需要实现网络隔离,同一租户的不同业务之间需要访问控制,边界防火墙很难灵活处理这些场景。因此,云平台引入新组件:安全组。安全组是一种分布式防火墙,专注东西向流量管控,支持云主机网卡级别的出入流量控制。
- 安全组规则的集合,支持添加、删除、修改规则,实现规则动作的管控。
- 已绑定网卡的集合,支持绑定云主机网卡,将安全组规则应用到云主机网卡上。
- 安全组未添加任何规则时,除组内成员可互通外,入方向默认拒绝所有流量,出方向允许所有流量。
- 安全组规则支持按需修改,包括:源IP、目标IP、目标端口、协议类型、优先级等。
- 安全组规则支持动态调整优先级,添加规则时可将规则插入到指定优先级,删除规则时优先级会自动调整,规则优先级始终保持连续。
- 云主机网卡支持挂载多个安全组,且安全组之间可动态调整优先级,默认情况下先挂载的安全组规则先生效。
技术原理
- 安全组规则组成
- 源:支持源数据(入方向)和目标数据(出方向)。
- 源类型:支持IPv4和IPv6类型。
- 协议类型和端口:支持ICMP、TCP、UDP等。
- 策略:拒绝或允许。
- 安全组规则优先级
- 安全组规则优先级是连续且不重复的(默认规则优先级为0,表示最高优先级),优先级数字越小,表示优先级越高。
- 默认情况下,添加的规则优先级最低。当从指定优先级插入时,后续规则优先级跟随自动调整,保证优先级不重复。
- 当有流量经过云主机网卡时,将从最高优先级的规则开始匹配,如果匹配成功则执行规则动作,否则再匹配后续规则。
- 安全组规则导入导出
- 对于已有的安全组内规则,支持一键导出。
- 支持将已导出的安全组规则再重新导入其它安全组,导入时提供规则校验。
- 网卡加载多个安全组
- 一个云主机网卡可挂载多个安全组,已挂载的安全组之间支持优先级排序,优先级数字越小,表示优先级越高。
- 当有流量经过云主机网卡时,将从最高优先级的安全组开始匹配,如果安全组内规则匹配成功则执行规则动作,否则再进入下一个安全组进行匹配。
- 网卡默认策略
- 默认情况下,网卡的入方向默认策略是允许,出方向默认策略是拒绝。默认策略支持修改。
- 当流量没有匹配到安全组规则时,会执行网卡的默认策略。
应用场景
- 不同业务访问控制以典型的Web应用为例。假定:
- Web云主机的TCP 80和443端口允许任意IP地址访问。
- App云主机的TCP 8080端口允许来自Web云主机的访问。
- DB云主机的TCP 3306端口允许来自App云主机的访问。
分别为三类业务云主机创建安全组,并配置相应规则,可实现不同业务之间的访问控制。
如图 1所示:图 1. 不同业务访问控制 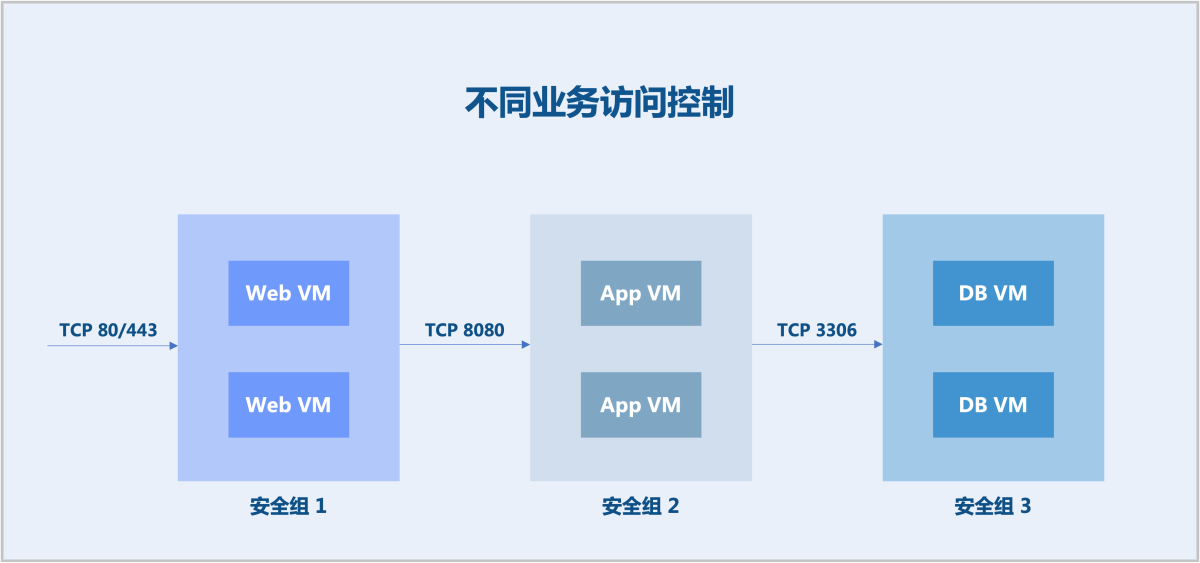
- 多业务共存上述业务云主机除提供业务能力外,还需允许运维控制(假定使用SSH协议),有两种实现方案:
- 方案1:为上述三个安全组分别新增一条规则。
- 方案2:创建一个新安全组,并挂载到上述所有业务云主机网卡上。
在本云平台中,云主机网卡支持挂载多个安全组,且方案2更灵活可控,首选方案2。可为上述每台业务云主机网卡配置两个安全组,且支持按需调整安全组优先级以及默认规则。
- 多级权限配置安全在IDC场景下,假定管理员不允许租户云主机访问某些外部网络,有两种实现方案:
- 方案1:管理员为项目配置默认安全组及规则,项目成员创建云主机将强制绑定该安全组。在项目成员视角下,该安全组可见但不可解绑。
- 方案2:管理员为租户云主机配置安全组及规则。在租户视角下,该安全组不可见也不可解绑。
- 组内云主机禁止互访
默认情况下,安全组内的云主机之间可互相访问,无任何规则限制。在某些场景下,要求同一安全组内的云主机之间不可互相访问,此时可将允许组内互通的默认规则停用。该条默认规则不支持删除。
VPC防火墙
VPC防火墙主要用于VPC网络环境下的南北向流量管控。VPC防火墙基于Iptables实现,其规则部署在VPC路由器中。为VPC路由器开启VPC防火墙,云平台自动向VPC路由器下发默认规则(编号10000)和系统规则(编号4000-9999)。默认规则和系统规则可保证缺省情况下VPC网络与外部网络的互访。
默认规则支持且仅支持修改,系统规则均不支持修改。此外,系统规则不支持添加或删除,但支持停用。用户配置自定义规则后,可按需修改默认规则、停用系统规则。在修改默认规则、停用系统规则前,请务必检查确认自定义规则符合预期,否则可能影响业务。
用户配置自定义规则,支持在公有网络或VPC网络上按需配置。
VPC网络与外部网络之间的安全规则建议配置在公有网络上。例如,不允许云主机-1访问外部网络,以及允许外部网络访问云主机-2,此时建议在公有网络的出方向配置规则。
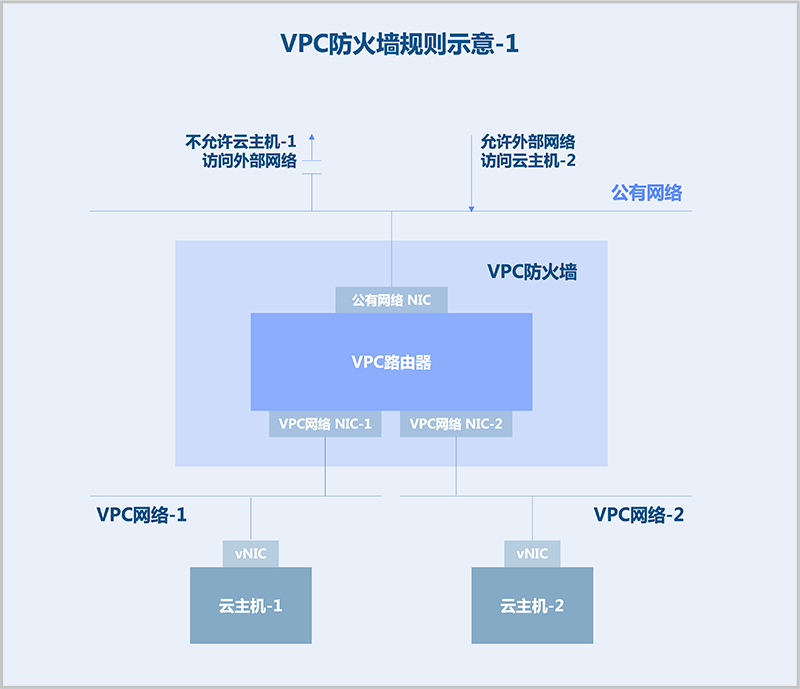
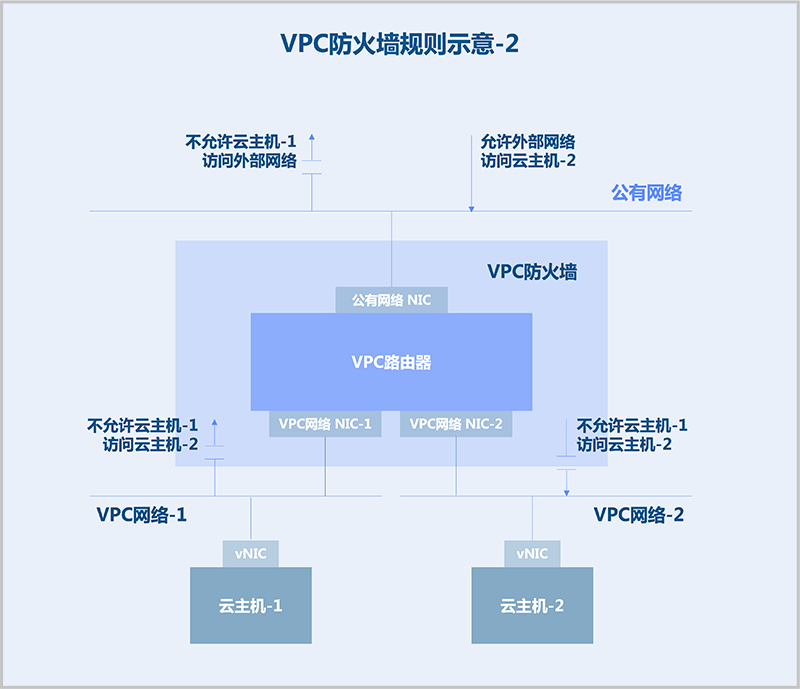
VPC网络之间的安全规则需配置在VPC网络上。例如,不允许VPC网络-1访问VPC网络-2,此时可在VPC网络-1的入方向配置拒绝规则,也可在VPC网络-2的出方向配置拒绝规则。
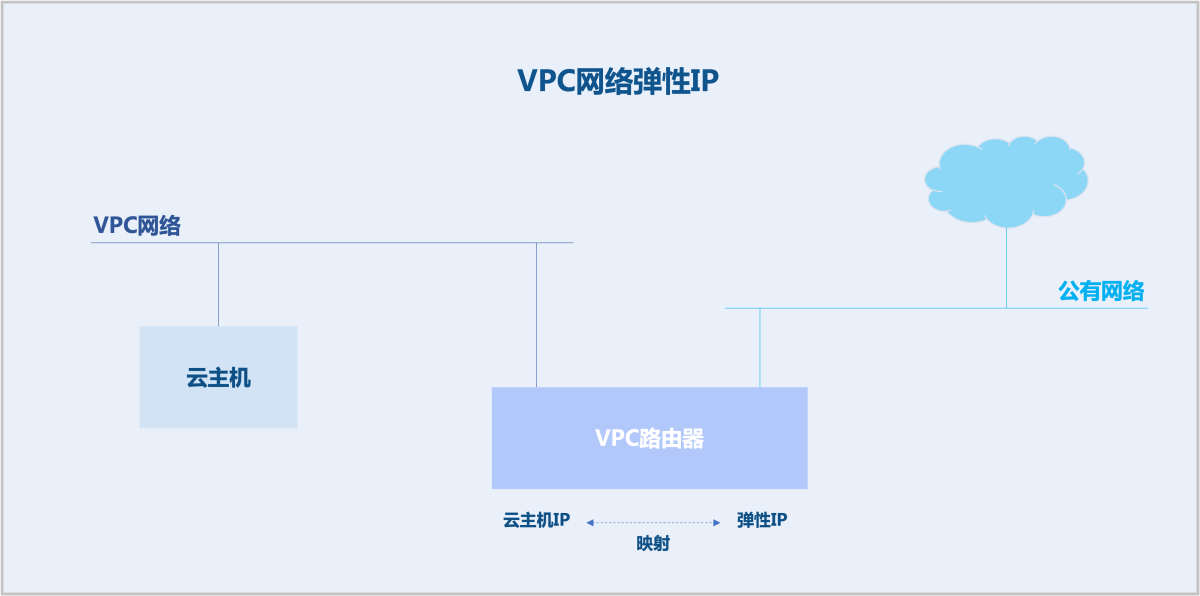
弹性IP
通常情况下,扁平网络与公有网络在二层上互相隔离,在三层上不可路由互通。扁平网络云主机不可访问公有网络,公有网络亦不可访问扁平网络云主机。此时,需使用弹性IP打通扁平网络与公有网络。
同样地,VPC网络与公有网络在二层上互相隔离,在三层上不可路由互通。若VPC路由器开启SNAT功能,VPC网络云主机可访问公有网络,但公有网络不可主动访问VPC网络。此时,需使用弹性IP打通VPC网络与公有网络。
技术原理
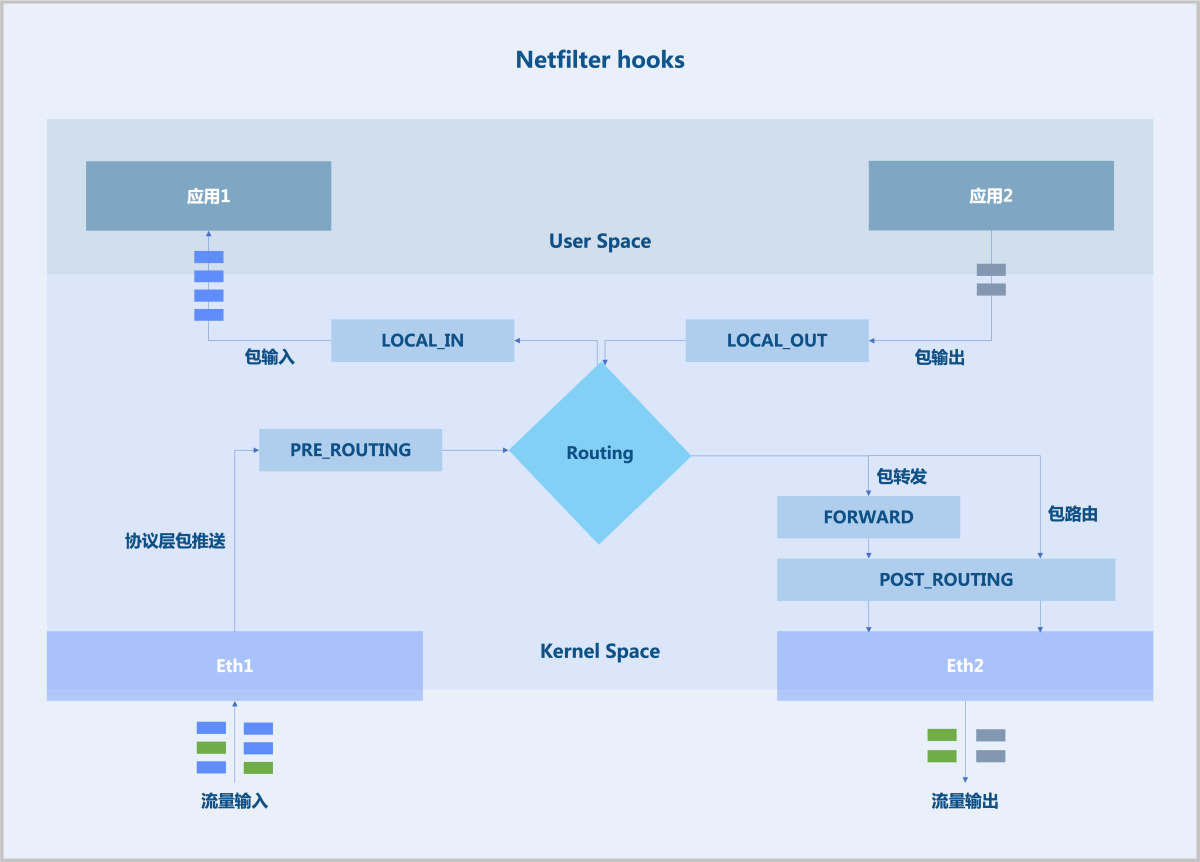
弹性IP基于Linux Netfilter实现。Netfilter是Linux内核中的一个网络子系统,用于实现包过滤、NAT和其它网络相关的Hook功能。Netfilter在报文转发路径上插入一系列Hook点,用户可通过Iptables工具在Hook点上添加规则来影响报文转发路径。
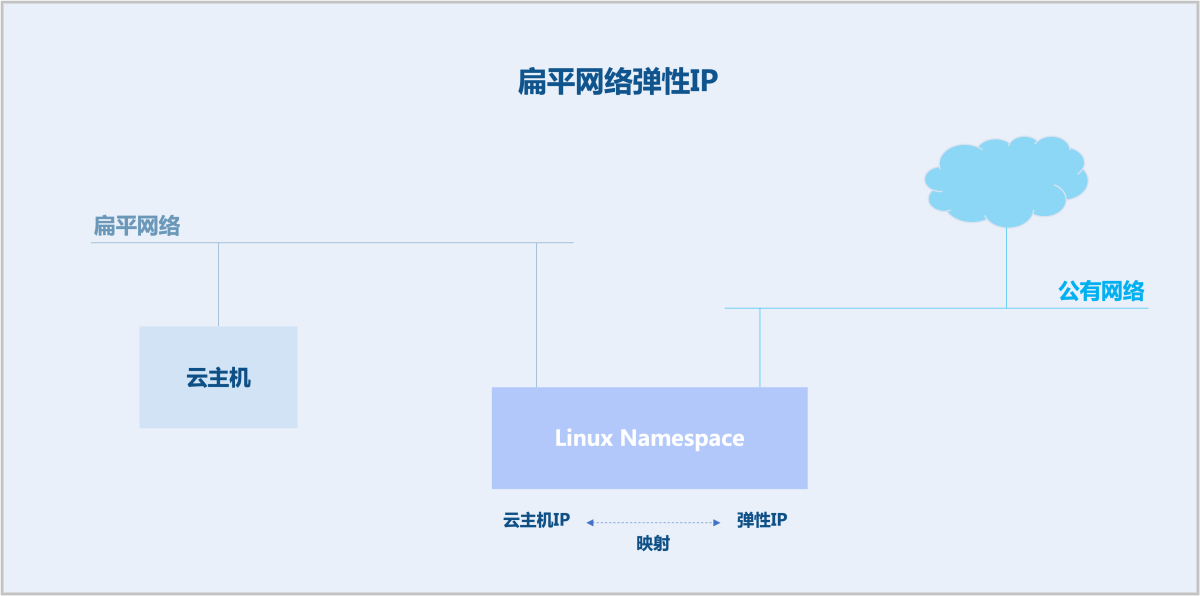
扁平网络弹性IP基于Linux Namespace来实现。需在云主机所属物理机上创建一个Linux Namespace,通过Linux Namespace实现云主机IP与弹性IP之间的映射。
VPC网络弹性IP基于VPC路由器来实现。通过VPC路由器实现云主机IP与弹性IP之间的映射,无需创建Linux Namespace。
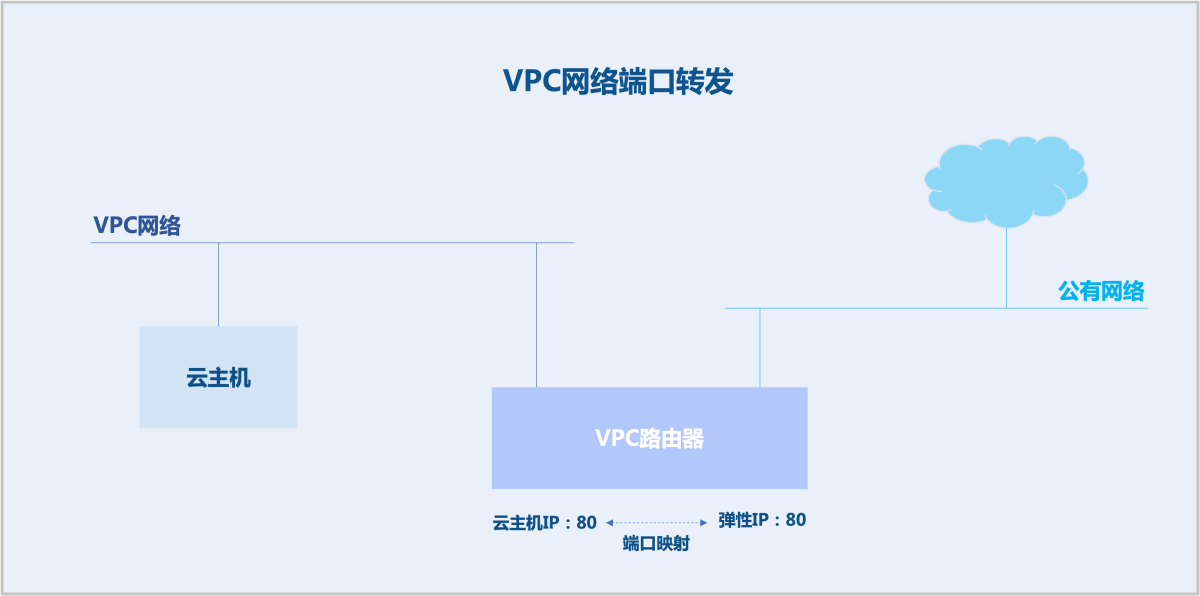
端口转发
通常情况下,扁平网络与公有网络在二层上互相隔离,在三层上不可路由互通。扁平网络云主机不可访问公有网络,公有网络亦不可访问扁平网络云主机。此时,需使用弹性IP打通扁平网络与公有网络。扁平网络不提供端口转发。
同样地,VPC网络与公有网络在二层上互相隔离,在三层上不可路由互通。若VPC路由器开启SNAT功能,VPC网络云主机可访问公有网络,但公有网络不可主动访问VPC网络。此时,需使用弹性IP打通VPC网络与公有网络。若用户希望云主机部分端口能被公有网络访问,则建议使用端口转发。
技术原理
同弹性IP,端口转发基于Linux Netfilter实现。Netfilter是Linux内核中的一个网络子系统,用于实现包过滤、NAT和其它网络相关的Hook功能。Netfilter在报文转发路径上插入一系列Hook点,用户可通过Iptables工具在Hook点上添加规则来影响报文转发路径。
扁平网络不提供端口转发。
VPC网络端口转发基于VPC路由器来实现。假定云主机业务监听在TCP 80端口,一方面希望外部用户可访问使用,另一方面又不能暴露全部TCP端口。此时,可使用端口映射。端口转发支持两种映射方式:单个端口到单个端口的映射、端口区间的映射。
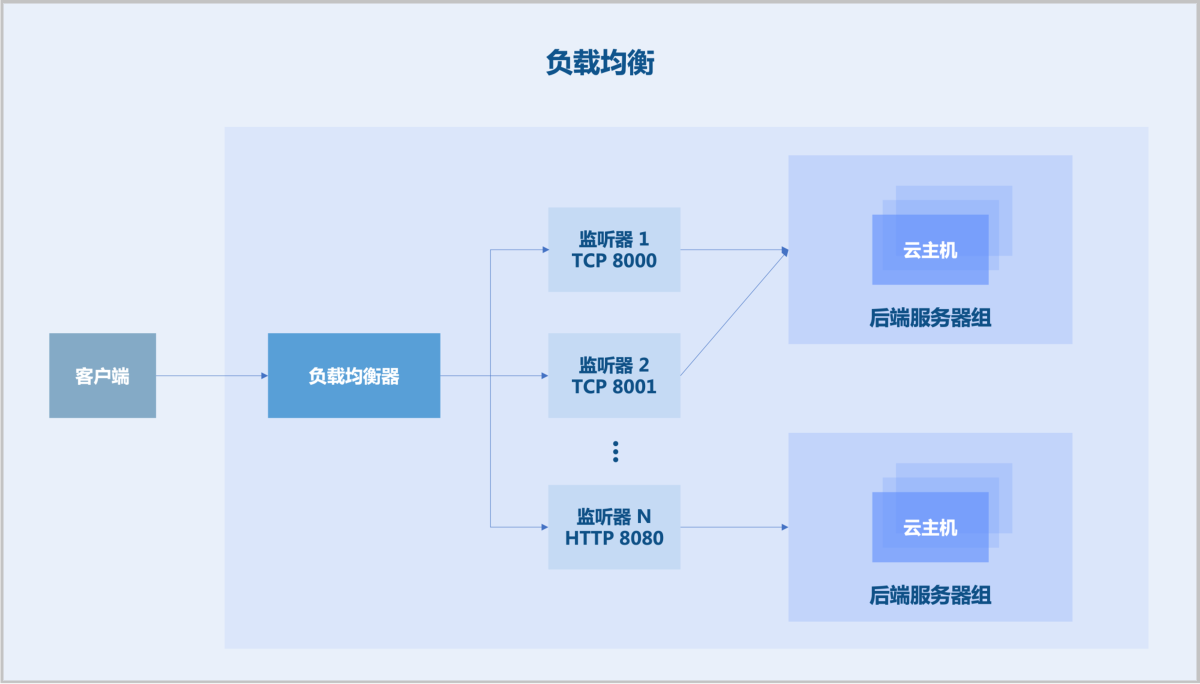
负载均衡
负载均衡提供各种灵活分配算法将全部网络请求均衡分布至后端服务器组上,通过合理管理流量分发以减轻单个服务器的负担,从而应对大流量、高并发的访问,满足客户业务场景需求。
- 轮询算法:按照顺序轮流分配访问请求至后端服务器。轮询是最简单的一个算法,无须关注后端服务器本身的连接数和系统负载等状态,适用于各个后端服务器性能差异不大的场景。
- 加权轮询算法:根据后端服务器权重转发访问请求。一般情况下,权重基于硬件配置进行设置,为静态值。权重值越高,被轮询的次数(概率)越高。加权轮询是轮询的一种特殊形式,适用于各个后端服务器性能差异较大的场景。
- 源地址哈希:使用客户端请求的源IP地址与目标IP地址生成唯一的哈希密钥,将请求分配给特定的后端服务器,适用于后端服务器需处理客户端请求差异较大的场景。
- 最小连接算法:将新的连接请求分配到当前连接数最小的后端服务器,适用于请求占用后端服务器时间相差较大的场景,常用于长连接服务。
- 四层会话保持机制:负载均衡将同一个源IP地址的访问请求都转发至一台后端服务器上。
- 七层会话保持机制:不同负载均衡算法下,七层会话保持机制不同。轮询算法或加权轮询算法使用基于Cookie的会话保持机制,负载均衡可通过Cookie将访问请求定向转发至之前记录的后端服务器。源地址哈希算法通过哈希函数计算客户端源IP地址,同一个源IP地址的访问请求都将转发至一台后端服务器上。
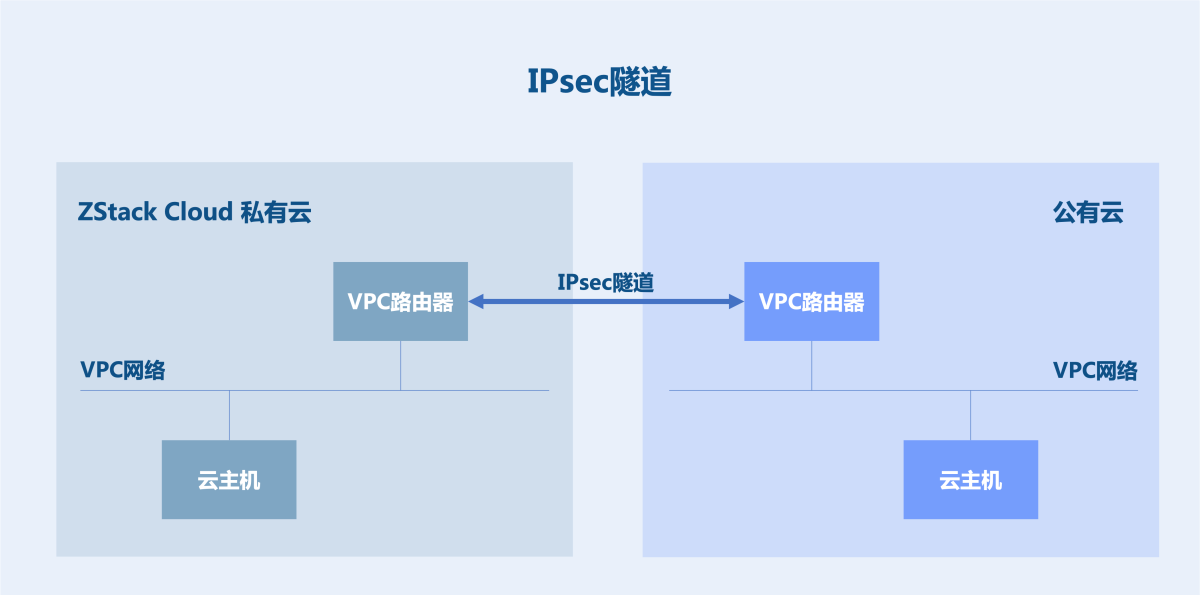
IPsec
用户在多个地域部署ZStack Cloud,或既部署ZStack Cloud私有云,又购买公有云服务。为将多云打通,IPsec隧道是一个简单易部署方案,可实现多云网络的三层互通,并确保多云之间数据传输的机密性和安全性。
ESP协议
- 传输模式(Transport Mode)
在该模式下,通常仅IP数据包的有效载荷部分会被加密或认证。由于原始IP报头(Original IP Header)未被修改或加密,因此路由保持不变。然而,当使用身份验证头(ESP Auth)时,为避免使哈希值失效,IP地址不能通过网络地址转换(NAT)进行修改。传输层和应用层总是通过哈希进行安全保护,因此它们不能以任何方式被修改,例如通过转换端口号。
如图 2所示:图 2. 传输模式-IP数据包 
- 隧道模式(Tunnel Mode)
在该模式下,整个IP数据包会被加密和认证。它会被封装到一个新的IP数据包中,并附加一个新的IP头(Outer IP Header)。隧道模式用于创建虚拟专用网络,用于网络到网络通信(例如:连接各个站点的路由器)、主机到网络通信(例如:远程用户访问)、以及主机到主机通信。隧道模式支持NAT穿越。
如图 3所示:图 3. 隧道模式-IP数据包 
ZStack Cloud IPsec支持隧道模式,不支持传输模式。
IKE协议
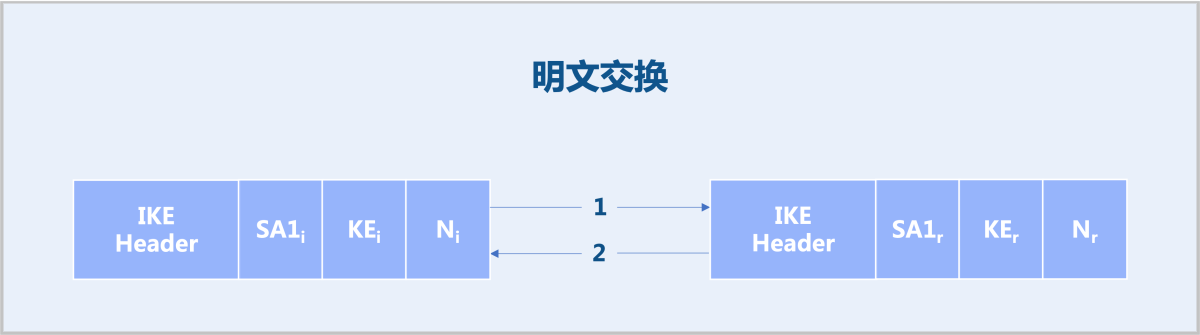
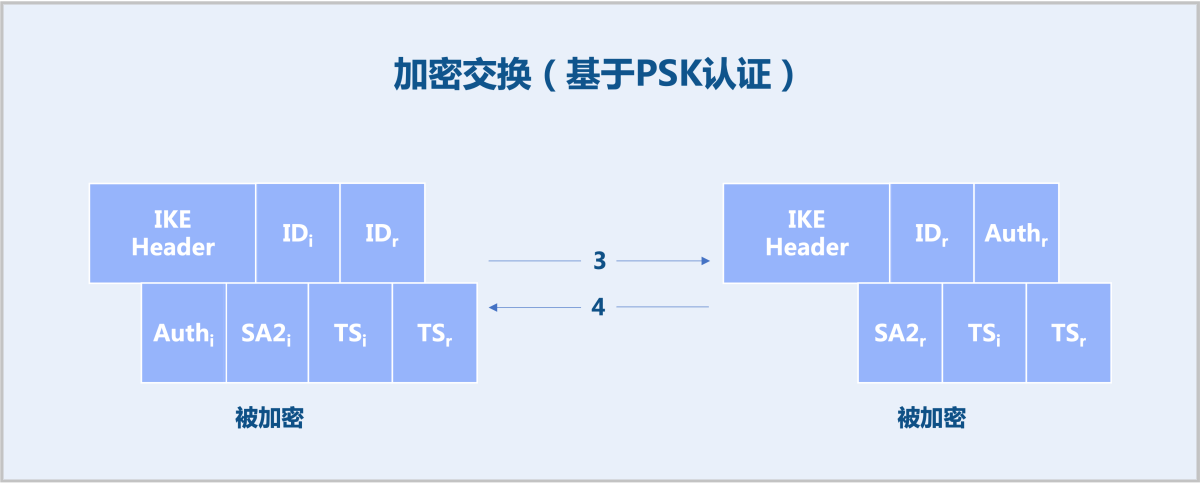
IKE有两个版本:IKEv1、IKEv2。ZStack Cloud IPsec推荐使用IKEv2。IKEv2可使用四条消息完成IKEv2 SA和IPsec SA的协商,简化了IKEv1的协商过程。
- 初始交换(Initial Exchanges)
- 创建子SA交换(Create_Child_SA Exchange)
- 通知交换(Informational Exchange)
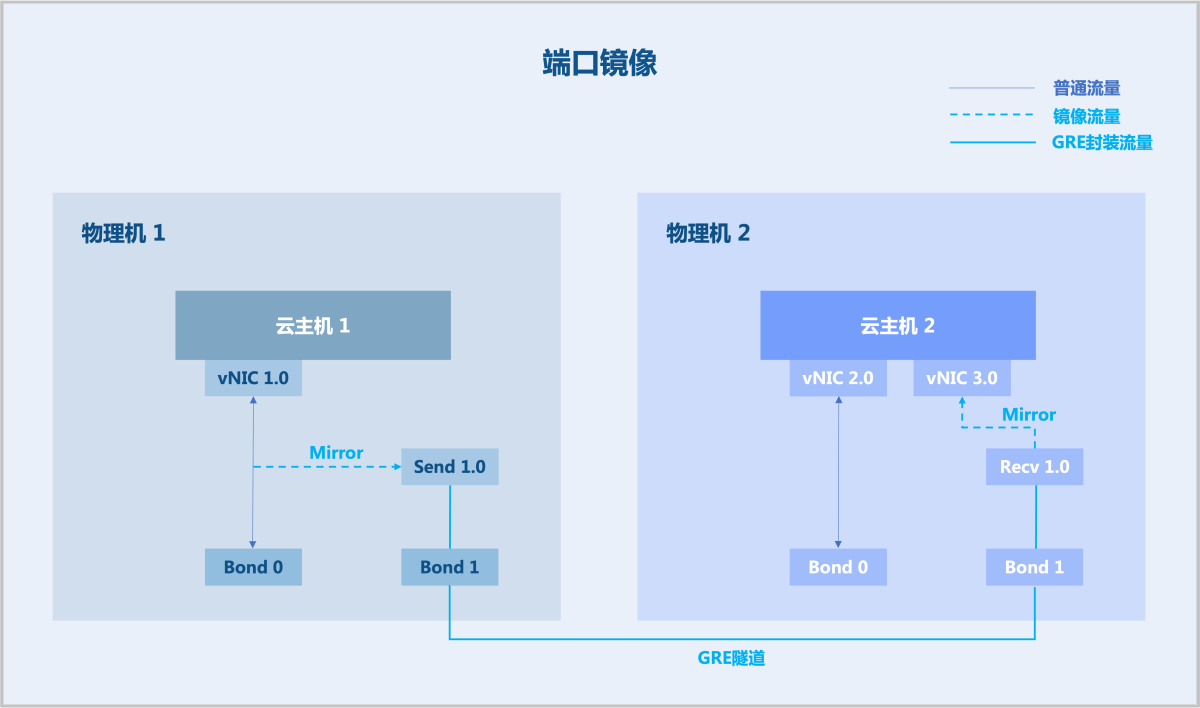
端口镜像
端口镜像将某个端口的报文复制转发至第二个端口,从而可在第二个端口上进行数据/流量分析,也可将流量继续转发至更远处再进行分析,最大程度降低对原始报文转发处理流程的影响。
原始报文通过的端口称为镜像端口,也称为被监控端口。上述第二个端口,即数据被复制转发到的端口,称为监控端口,也称为采集端口或观察端口。
- 入方向,仅对从镜像端口接收的报文进行复制转发。
- 出方向,仅对从镜像端口发送的报文进行复制转发。
- 对从镜像端口接收和发送的报文都进行复制转发。
- 当怀疑有攻击或有网络故障时,需获取某个端口的报文进行分析,从而排除威胁,找出故障原因。
- 需对某个端口的流量进行监控与观察,同时还需尽量确保不影响原始报文转发。
技术背景
- 端口:将指定端口接收或发送的报文复制到观察端口,此时的镜像被称为端口镜像。
- VLAN:将指定VLAN内所有活动接口接收的报文复制到观察端口,此时的镜像被称为VLAN镜像。
- MAC地址:将指定VLAN内源MAC地址或目的MAC地址为指定MAC地址的报文复制到观察端口,此时的镜像被称为MAC镜像。
- 报文流:将符合指定规则的报文流复制到观察端口,此时的镜像被称为流量镜像。
云平台十分重视弱化用户资源的物理位置,因此类似于物理交换机的ERSPAN技术,云平台的端口镜像将用户某个端口的报文/流量复制转发至任意位置的设备(很多情况下使用虚拟资源,例如云主机),再在远端进行检测和分析。
技术原理
在ZStack Cloud中,网络虚拟化基于开源Linux操作系统实现,对应的端口镜像功能基于Linux系统生态工具/库来实现。
- 在物理机1上创建另一个端口:Send 1.0。
- 创建一个独立于业务网络的特殊网络:流量网络。
- 将vNIC 1.0的流量镜像到Send 1.0。
- 在Send 1.0和Recv 1.0之间建立GRE隧道。
- 镜像数据通过GRE隧道转发至云主机2上。
其中,流量镜像使用Linux流量控制工具TC(Traffic Control)来实现。GRE隧道运行在独立的流量网络上,从而可将报文/流量复制转发至云平台任意位置。
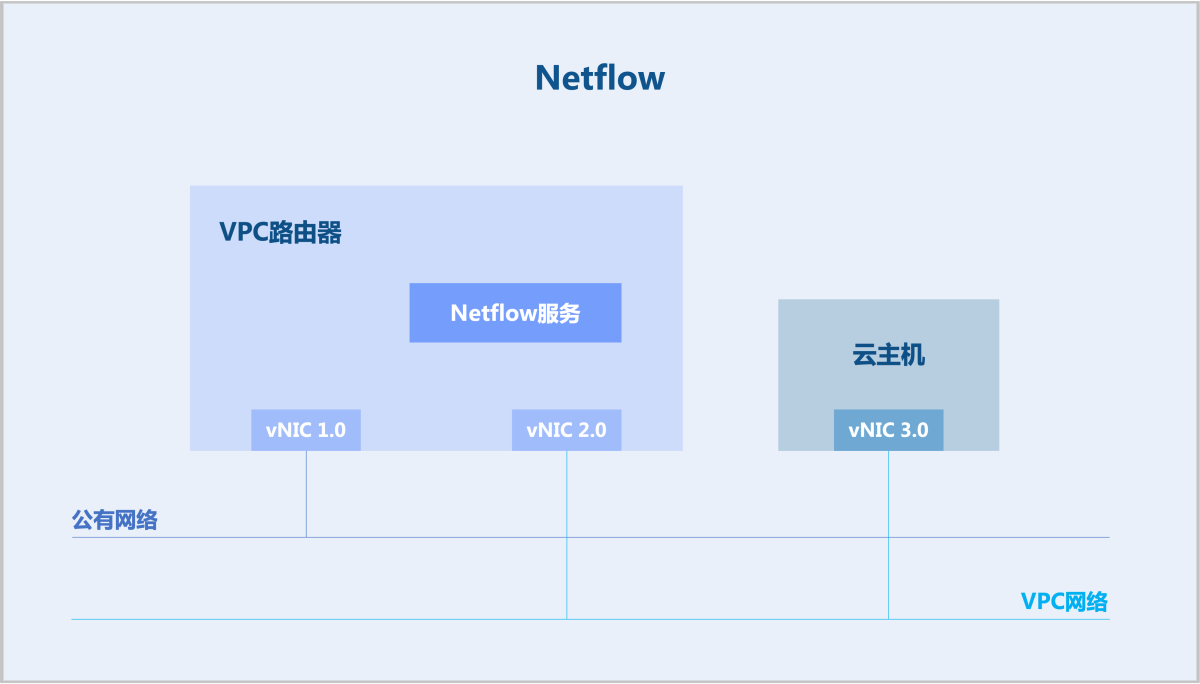
Netflow
NetFlow是一种流量统计技术,在网络流量统计、网络规划、网络安全等领域有广泛应用。NetFlow起源于思科公司的一项专有技术研发,其它网络设备厂商现已普遍支持。NetFlow应用最广泛的是V5和V9版本,例如:IETF的技术标准IPFIX(IP Flow Information Export)正是基于V9版本开发。
- 探测器(Exporter):运行在网络设备上,收集当前设备接收、转发、发送的网络流量信息。
- 采集器(Collector):接收来自探测器的NetFlow信息,并存储这些信息。
- 分析器(Analyzer):根据采集器的信息,进行流量统计,分析是否存在网络拥塞,是否存在流量攻击等。
在ZStack Cloud中,VPC路由器可作为Netflow探测器,向采集器发送Netflow信息。
技术原理
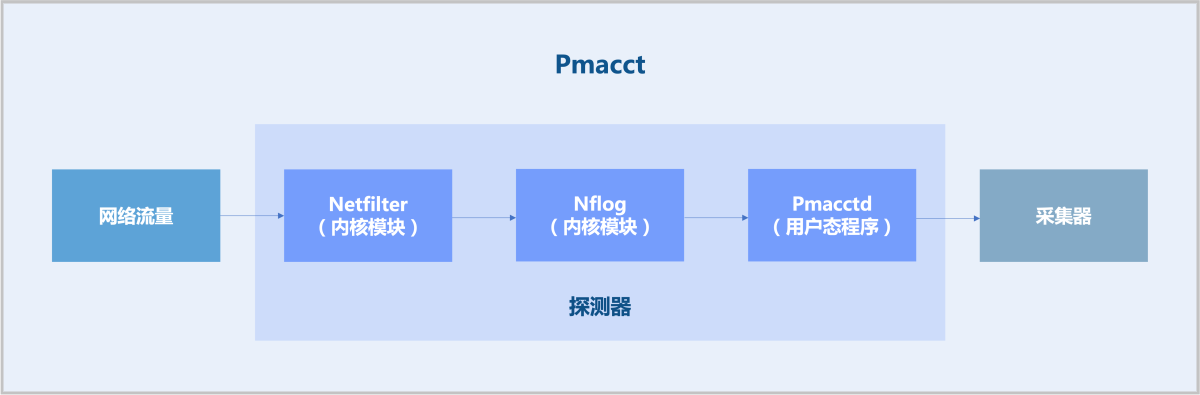
- 内核模块:添加Iptables规则,需要监控的流量Target是Nflog。例如:
iptables -t raw -A VYATTA_CT_PREROUTING_HOOK -i eth1 -j NFLOG --nflog-group 2 # 每个Netflow服务建立时自动生成的一行网络配置 # eth1: 相应网络在VPC路由器内部的接口名称 # nflog-group 2: 指定一个Nflog ID, 需在Iptables和Pmacctd中配置一致 - 用户态程序:用户态的Pmacctd通过Nflog的Netlink接口从内核读取流量信息、分析流量信息、转化成Netflow信息、发送至采集器。
OSPF
| 序号 | 解决方案 | 详情 |
|---|---|---|
| 1 | 静态路由 |
|
| 2 | OSPF |
|
| 3 | 源进源出(特定场景) |
|
本章主要介绍OSPF动态路由协议。
技术原理
OSPF(Open Shortest Path First)是IETF组织开发的一个基于链路状态的动态路由协议。OSPFv2用于解决IPv4路由同步,OSPFv3用于解决IPv6路由同步。ZStack Cloud支持OSPFv2。
- RouterID
- 路由器ID,是一个32位整数,在OSPF系统中唯一标识一台OSPF路由器。
- 区域
- 在一个大型网络系统中,可能会出现诸如路由信息过多、路由计算时间过长、路由收速度敛慢等问题,任何一个网络变化,均会导致所有路由器重新计算路由,从而引发路由震荡。OSPF通过将大型网络划分成多个区域来解决这一问题,每个区域有一个区域ID。
- 根据LSA分发情况,区域可分为:普通区域、Stub区域、NSSA区域、Totally NSSA区域。
- 如图 1所示:
图 1. 区域 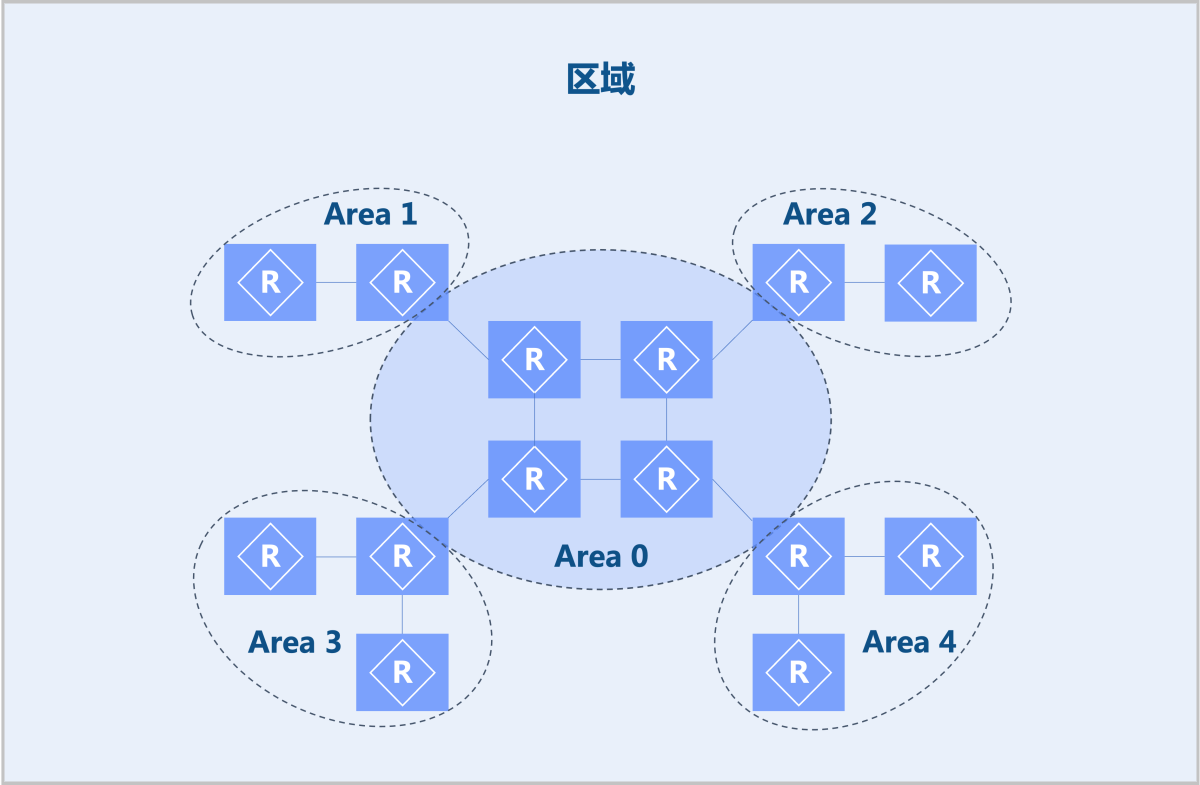
- 邻居关系和邻接关系
- 路由器启动OSPF协议后,会定时打开OSPF功能接口发送OSPF Hello报文。收到Hello报文的设备,比较Hello报文中的参数和接口参数(例如:区域ID),若参数一致,则形成邻居关系。
- 形成邻居关系后,若两端设备成功交换DD报文和LSA报文,则建立邻接关系。
- 不是所有的邻居关系都会变成邻接关系。
- DR/BDR/DROther
- 在广播网或NBMA网络中,可能同时存在很多OSPF路由器,不需要两两之间形成邻接关系。因此,需要选举出DR(指定路由器)和BDR(备份指定路由器),其它的路由器则称为DROther(非指定路由器)。
- 仅当DR、BDR、以及全部路由器形成邻接关系时,才可减少OSPF报文交换,加速路由计算。
- DR和BDR通过选举算法产生,选举参数包含:OSPF接口优先级、RouterID等。在实践中尽量让物理路由器选举为DR和BDR,因为VPC路由器可能因为云平台操作导致关机,从而影响整个数据中心的网络抖动。
- 如图 2所示:
图 2. 选举前后对比 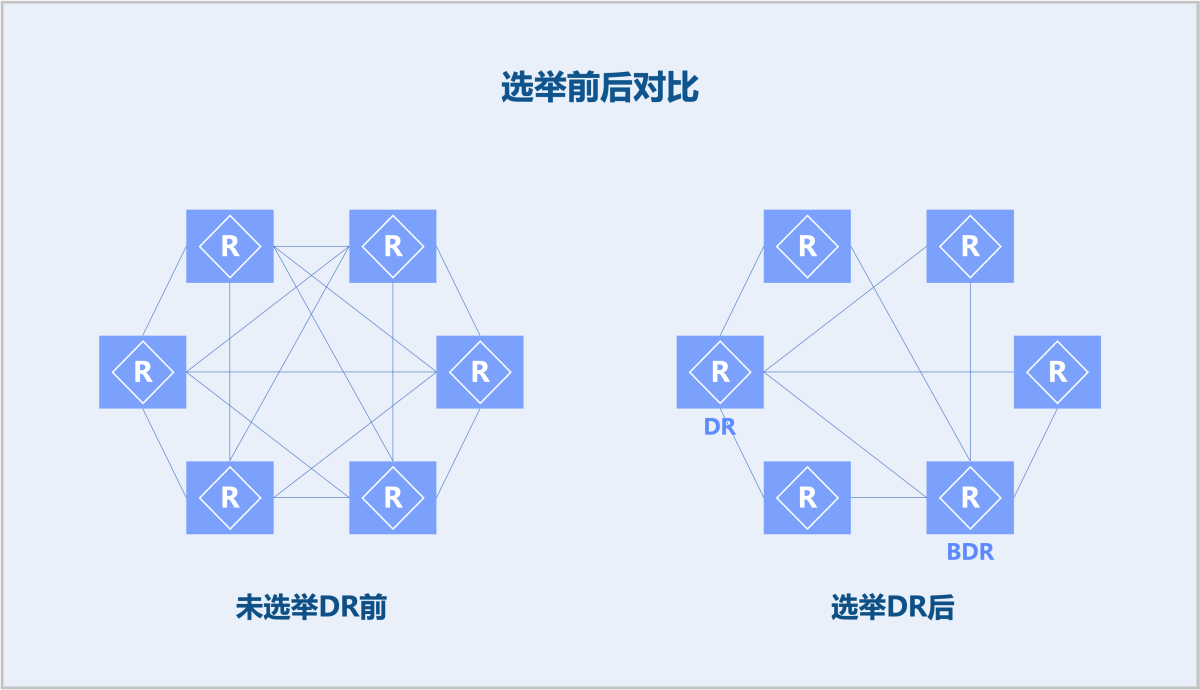
- LSA
- OSPF是基于网络拓扑信息计算路由信息的协议,LSA(链路状态)用于描述网络拓扑状态。
LSA类型 描述 Type 1 每个OSPF路由器产生一条Type 1 LSA,描述了设备的链路状态和开销,在所属的区域内传播。 Type 2 由DR(指定路由器)生产,描述一个广播网连接的OSPF路由器,在所属的区域内传播。 Type 3 ABR(区域边界路由器)产生,把区域内网段的路由发布到其它区域。 Type 4 ABR(区域边界路由器)产生,描述到ASBR的路由信息。 Type 5 ASBR(自治域边界路由器)产生,把区域外路由发布到相关区域。
- OSPF是基于网络拓扑信息计算路由信息的协议,LSA(链路状态)用于描述网络拓扑状态。
组播
- 单播:信息源需对每个接收者复制并发送一份数据。缺陷:若接收者成千上万,将给信息源造成巨大负载压力,同时信息源的网络带宽承受巨大压力。
- 广播:信息源发送一份广播数据,让交换机来复制。缺陷:不能跨三层进行转发;不是接收者的设备也收到信息,信息安全无法保障,浪费大量带宽。
- 组播:组播源仅需发送一份数据,该数据在距离组播源尽可能远的网络节点才开始复制和分发。相较单播与广播,节约网络带宽,降低网络负载,提高信息传输安全性。
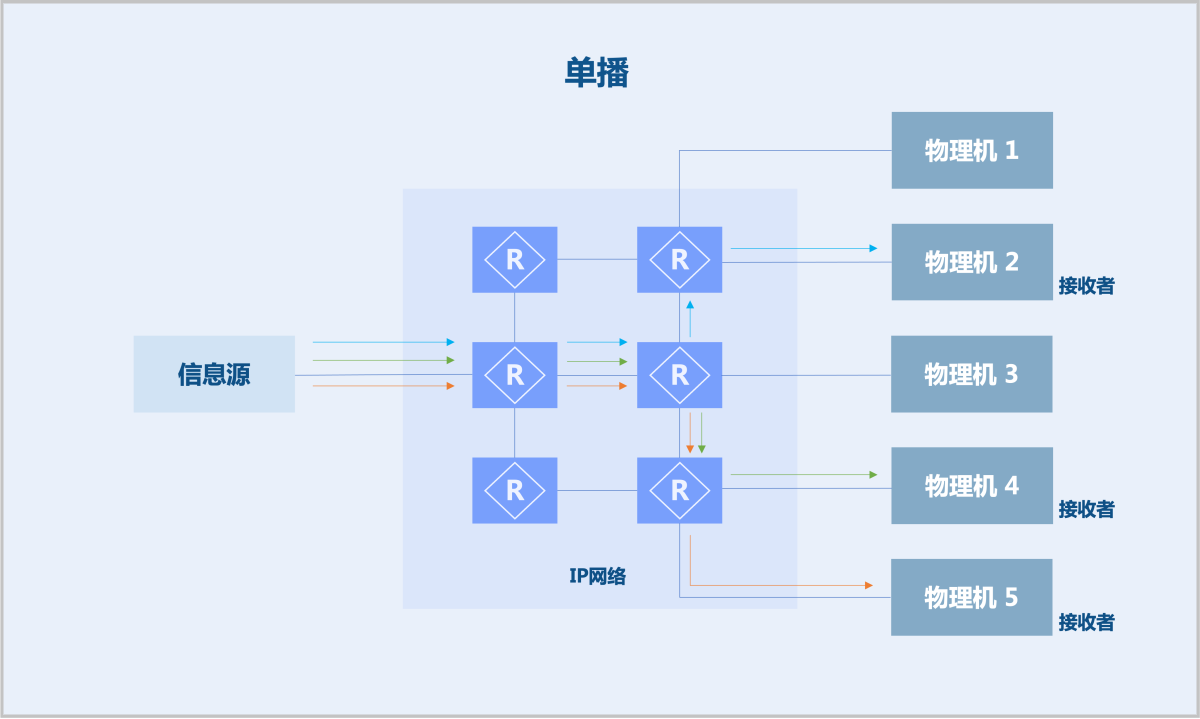
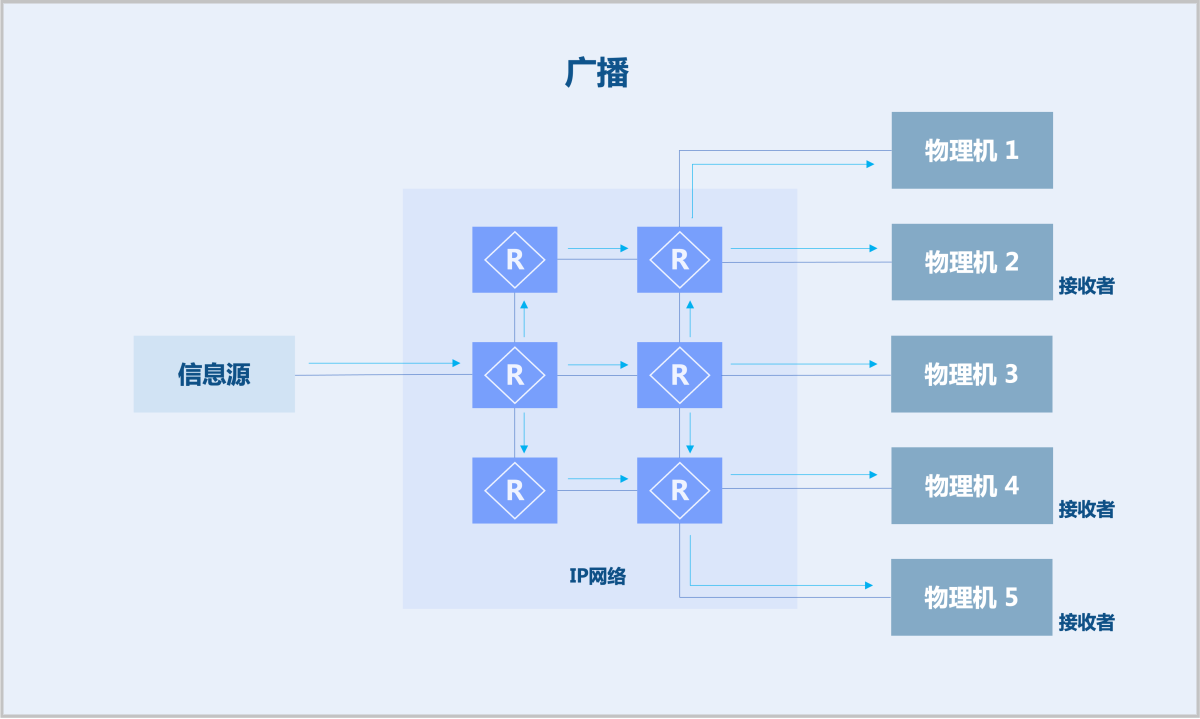
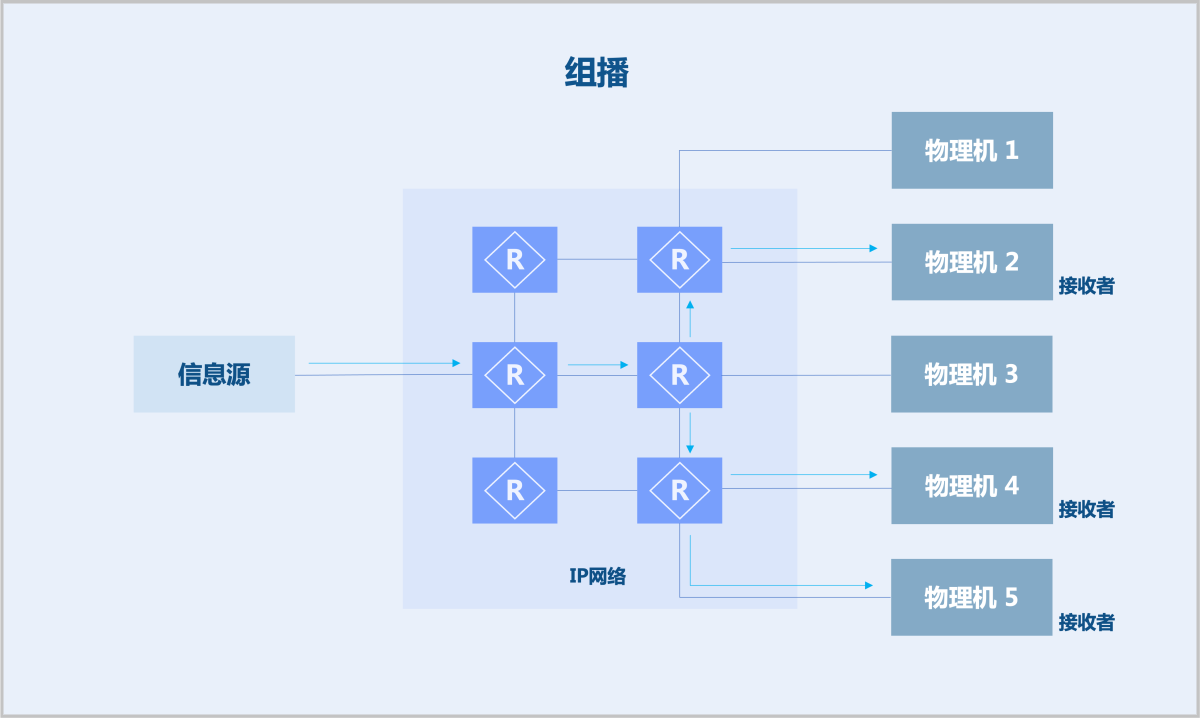
由此可见,组播技术能够有效解决单点发送、多点接收的问题。该技术在网络电视、在线直播、远程教育、远程医疗、实时视频会议等领域(对带宽和实时数据交互要求较高)已有广泛应用。
组播地址
| 范围 | 用途 |
|---|---|
| 224.0.0.0 ~ 224.0.0.255 | 保留地址。例如:OSPF使用224.0.0.5,VRRP使用224.0.0.18 |
| 224.0.1.0 ~ 238.255.255.255 | 用户可用的组播地址 |
| 239.0.0.0 ~ 239.255.255.255 | 本地组播地址 |
组播成员管理
组播注册协议用来在交换机和路由器上维护组播组和组播接收者之间的关系。
- IGMPv1:定义了基本的组成员查询和报告过程。
- IGMPv2:增加了组成员快速离开的机制等。
- IGMPv3:增加对SSM模型的支持等。
组播转发树
- 源树(SPT):以组播源作为树根转发树。网络要为任何一个向该组发送报文的组播源建立一棵树,路由表的规模非常大。SPT同时适用于PIM-DM网络和PIM-SM网络。
- 共享树(RPT):以某个路由器作为树根,该路由器称为汇集点(RP),以RP到所有接收者的最短路路径所共同构成的转发树。每个组播组,网络中只维护一棵树。组播源先向树根(RP)发送数据报文,再按照共享树转发到达所有的接收者。RPT适用于PIM-SM网络。
组播路由协议
常用的组播路由协议:PIM协议。PIM协议有三种工作模式:PM-DM、PM-SM、PIM-SSM模式。
QoS
QoS (Quality of Service) 是带宽管理和质量服务。在现代网络环境中,QoS是确保网络效率和性能的关键。有效的带宽控制可以优化资源分配、改善用户体验,尤其在多媒体传输和企业级应用中尤为重要。
- 网卡QoS:支持为指定网卡单独设置QoS,为该网卡单独提供带宽资源和限速服务。
- 虚拟IP QoS:支持为指定虚拟IP单独设置QoS,为使用虚拟IP的网卡提供带宽资源和限速服务。用户可以针对一个虚拟IP的不同端口配置多条QoS规则。
- 共享带宽:共享带宽是可供多个虚拟IP使用的QoS服务,加入同一条共享带宽的虚拟IP共享相同的带宽资源并被集中限速。目前,ZStack Cloud共享带宽仅供公网虚拟IP使用。公网虚拟IP是VPC网络上云主机访问公网的主要窗口,例如,基于公网虚拟IP创建弹性IP并绑定VPC云主机网卡,该云主机可以通过虚拟IP和公网通信。如果多台云主机使用的虚拟IP同属于一条共享带宽,则这些云主机在访问公网时,使用相同的带宽资源并被集中限速,是节省公网访问成本的有效路径。如图 1所示:
图 1. 共享带宽原理图 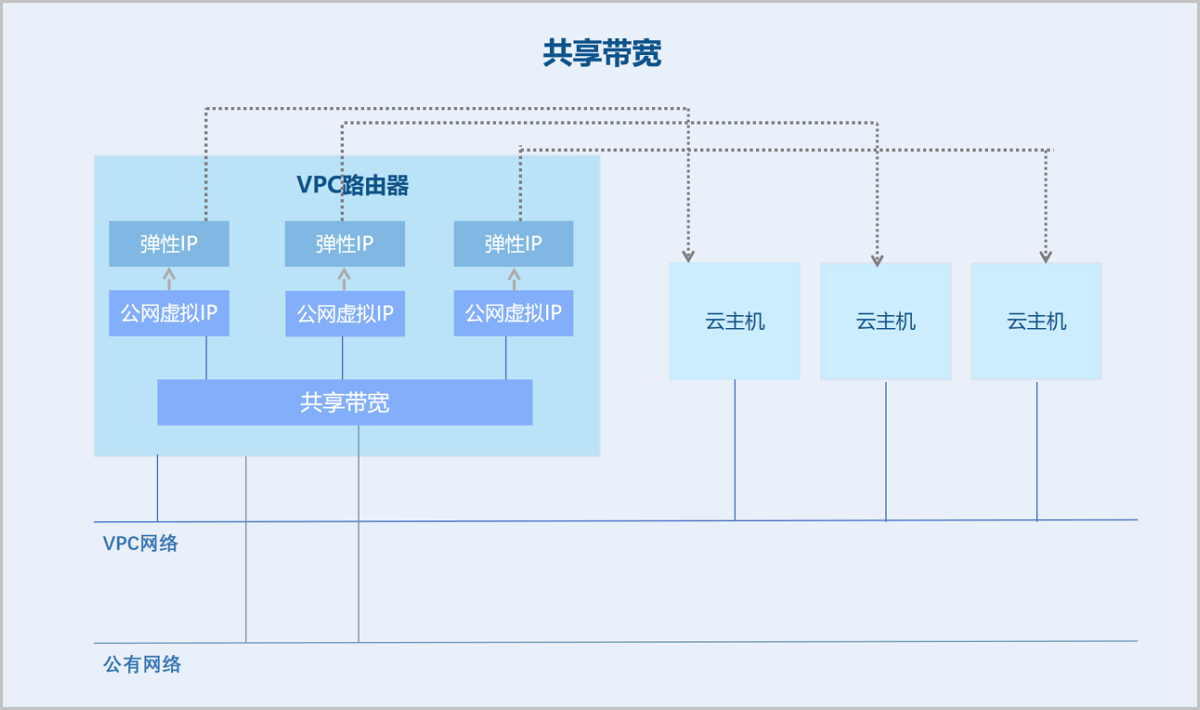
- qdisc (队列规则):定义如何处理经过接口的数据包,它们可以用来排队、丢弃、重新排列或重新标记数据包。
- class (分类):在支持分类的qdisc中,流量可以被分进不同的类别,每个类别可以设置单独的队列规则和带宽限制。
- filter (过滤器):分类数据流,判断数据包所属的class,过滤器可以根据端口号、IP地址等多种标准进行数据流分类。
- 根据指定的QoS策略定义qdisc和class:
- 定义一个根qdisc,通常是HTB (分层令牌桶),创建层次化带宽管理架构。
- 在qdisc下创建class,每种class代表一种不同的流量策略,并为class配置带宽限制。
- 配置filter:根据指定的QoS策略,为class配置filter,确保访问流量被正确分类到对应的class中。
- 监控和调整:使用tc命令监控流量和类别的性能,并根据监控结果调整带宽分配和策略,保持网络性能和响应。