运维管理
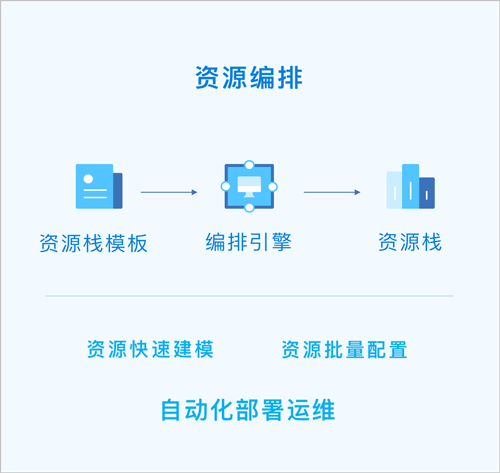
资源编排
资源编排:一款帮助云计算用户简化云资源管理和自动化部署运维的服务。通过资源栈模板,定义所需的云资源、资源间的依赖关系、资源配置等,可实现自动化批量部署和配置资源,轻松管理云资源生命周期,通过API和SDK集成自动化运维能力。
功能优势
- 用户只需创建资源栈模板或修改已有模板,定义所需的云资源、资源间的依赖关系、资源配置等,资源编排将通过编排引擎自动完成所有资源的创建和配置。
- 云平台提供示例模板,也可使用可视化编辑器,快速创建资源栈模板。
- 可根据业务需要,动态调整资源栈模板,从而调整资源栈以灵活应对业务发展需要。
- 如果不再需要某资源栈,可一键删除该栈及栈内所有资源。
- 可重复使用已创建的资源栈模板快速复制整套资源,无需重复配置。
- 可根据业务场景灵活组合云服务,以满足自动化运维的需求。
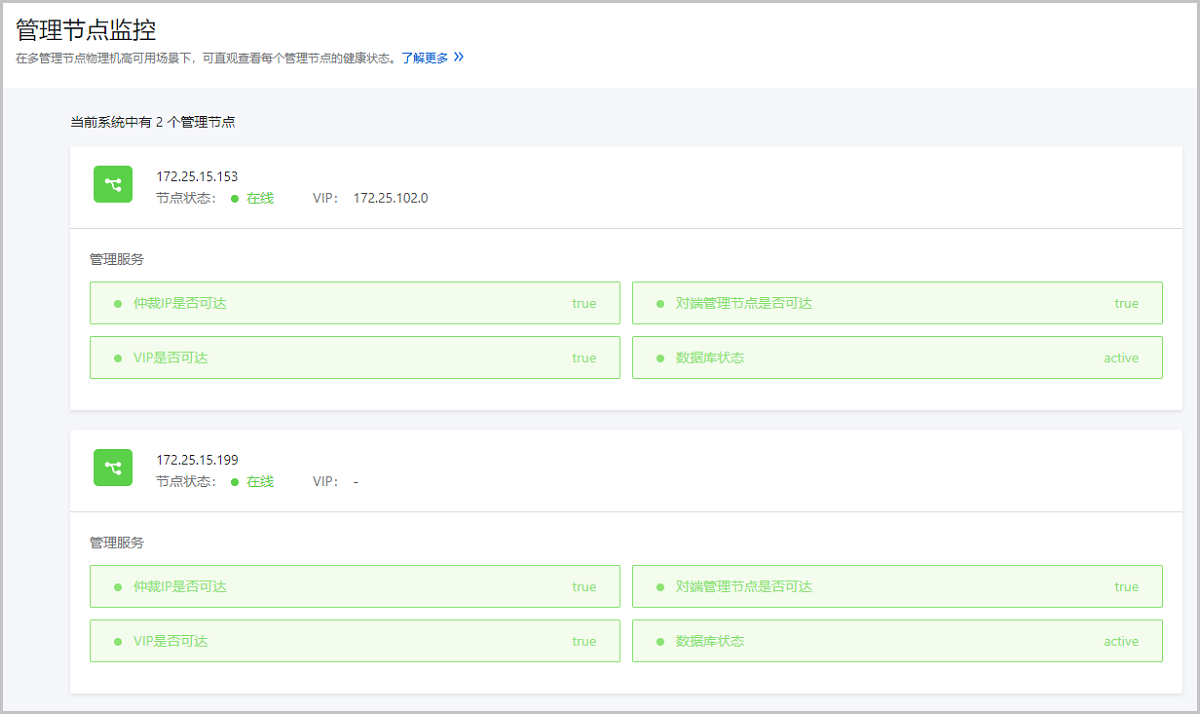
管理节点监控
在双管理节点物理机高可用场景下,可直观查看每个管理节点的健康状态。
- 仲裁IP是否可达:监控用于判断主备管理节点的仲裁IP是否可达,若不可达可能导致管理节点高可用功能失效。
- 对端管理节点是否可达:监控备管理节点是否可达,若备管理节点不可达,无法与备管理节点通信。
- VIP是否可达:监控VIP是否可达,若VIP不可达,主管理节点不能通过VIP访问UI界面。
- 数据库状态:监控数据库状态,若数据库异常或双管理节点数据库不同步,可能存在数据丢失风险,请及时恢复故障。
监控报警
监控报警支持对时序化数据(如资源负载数据和资源容量数据)以及系统中发生的预定义事件进行监控,并通过通知服务(SNS)推送报警消息至指定的通知对象。支持资源报警器、事件报警器和扩展报警器三种报警器类型,支持系统/邮箱/钉钉/企业微信/飞书/Webhook/短信/Microsoft Teams/SNMP Trap接收端通知对象类型,部分资源报警器需安装agent才能使用。
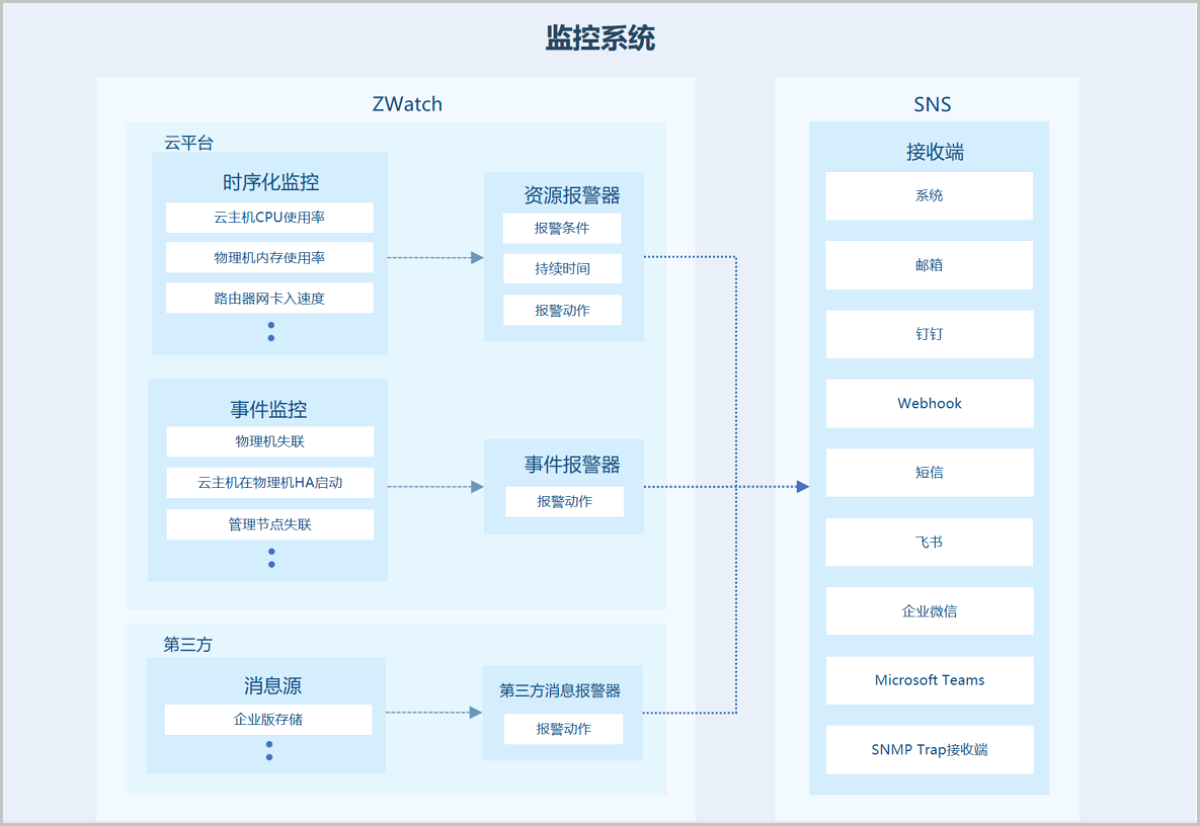
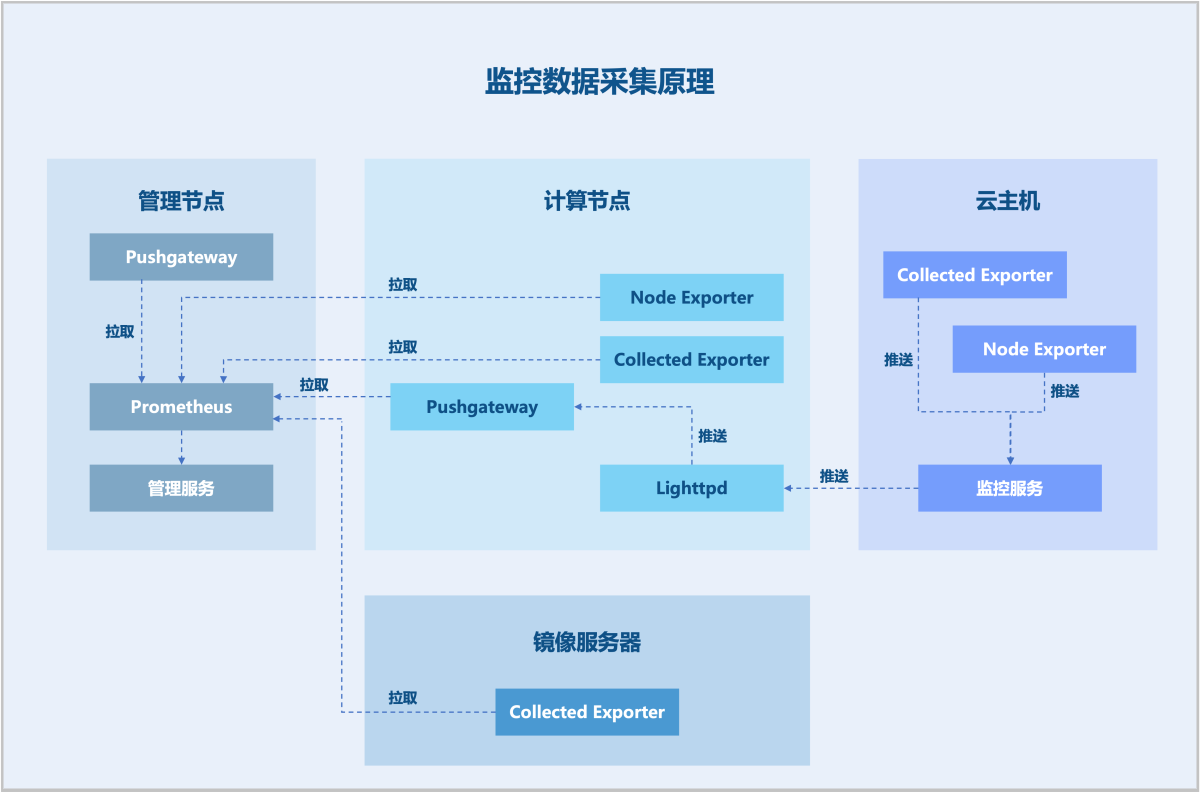
时序监控数据由Prometheus提供,在监控业务数据时,需将不同数据汇总,由Prometheus统一收集。
在Prometheus架构设计中,Prometheus服务器并不直接服务监控特定目标,其主要负责数据的收集、存储,并对外提供数据查询支持。因此,为监控到样本数据,如:物理机CPU使用率,需通过Exporter周期性采集监控样本。云平台针对不同监控目标,分别使用拉取模式和推送模式来采集监控数据。当物理机或云主机外部监控作为监控目标时,Prometheus服务会周期性使用拉取模式采集物理机上Exporter收集到的数据。
另外,由于网络问题或安全问题,Prometheus无法直接访问到云主机内部或裸金属服务器内部,此时需一个Pushgateway作为中间者完成中转工作,采集端仍通过Exporter采集监控数据, 并采用推送方式周期性将数据推送给Pushgateway,随后Prometheus采用拉取方式采集Pushgateway数据,从而完成数据的统一收集。
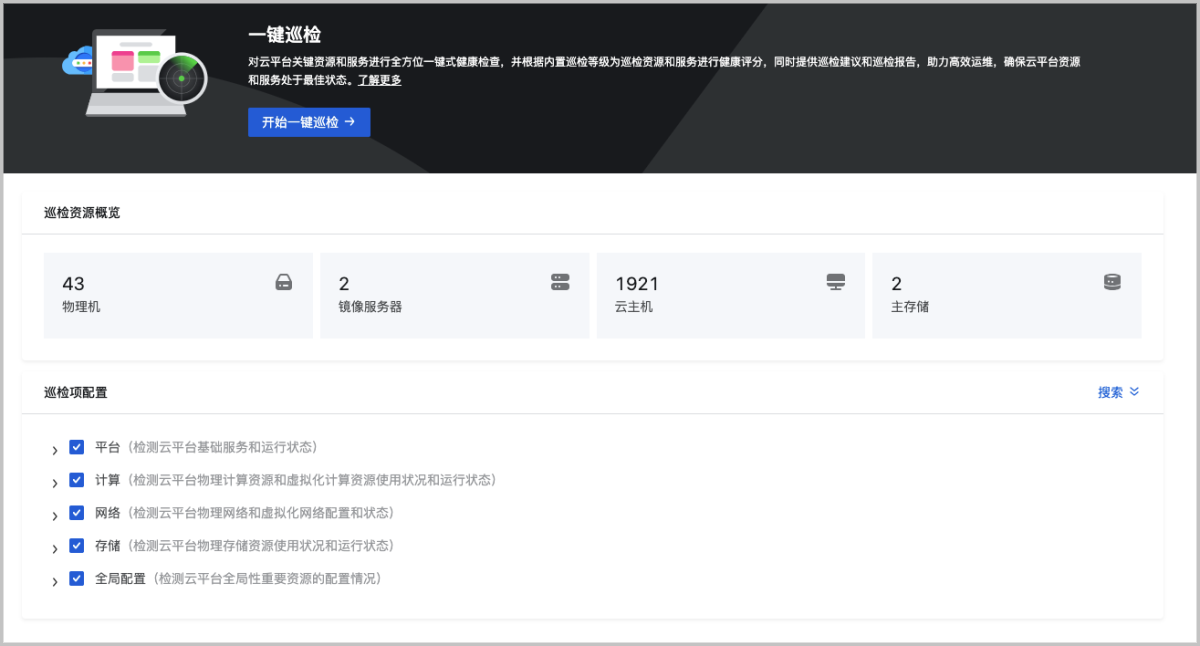
一键巡检
一键巡检支持对关键资源和服务进行全方位一键式健康检查,并根据巡检结果为巡检资源和服务进行健康评分,同时提供巡检建议和巡检报告,助力高效运维,确保云平台资源和服务处于最佳状态。一键巡检适用于需要对云平台进行集中高效运维场景。
- 平台:检测云平台基础服务和运行状态。
- 计算:检测云平台物理计算资源和虚拟化计算资源使用状况和运行状态。
- 网络:检测云平台物理网络和虚拟化网络配置和状态。
- 存储:检测云平台物理存储资源使用状况和运行状态。
- 全局设置:检测云平台全局性重要资源的配置情况。
用户可自定义根据类别选择巡检项进行一键巡检,启动巡检后,云平台将对所选择的巡检项涉及的资源或服务进行健康检查。一键巡检内置健康评分机制,支持对所巡检的资源或服务的健康状态进行量化评分,帮助用户直观准确把握云平台整体运行状态。