场景挑战与应对
在AI模型推理场景中,用户主要面临以下挑战:
- 高并发请求的性能瓶颈:当系统需要处理大量请求时,单个模型推理的计算代价高,可能导致响应延迟增加或服务不可用。
- 不同硬件资源的利用效率低:GPU、CPU等资源未被充分利用,可能因推理任务的分布不均造成性能浪费。
- 复杂的服务部署与扩展:AI模型从开发到生产环境的部署流程繁琐,缺乏统一的管理工具,难以快速迭代。
ZStack AIOS提供一套预置推理服务模板,便于处理批量AI推理,同时帮助用户快速部署和使用常用模型。
技术特色:
- 提供批量推理技术,将多个推理请求合并为一个批次,从而提高硬件资源利用率和吞吐量。
- 提供灵活、高效的工具链,支持模型的快速部署和高性能生产级推理服务。
- 自动化资源调度与服务扩展,降低对底层基础设施的依赖。
- 扩展性高,允许用户选择使用Huggingface、或完全自定义推理服务框架。
自适应批量推理 (Adaptive Batching)
通过在所有推理服务中设定一个调度程序,负责监督将请求收集到批次中,直至满足批次窗口或批次大小的条件,此时批次被发送到模型进行推理。通过批量推理,可最大限度利用GPU等并行计算资源,避免资源空闲或单次推理计算的低效。
如图1所示:
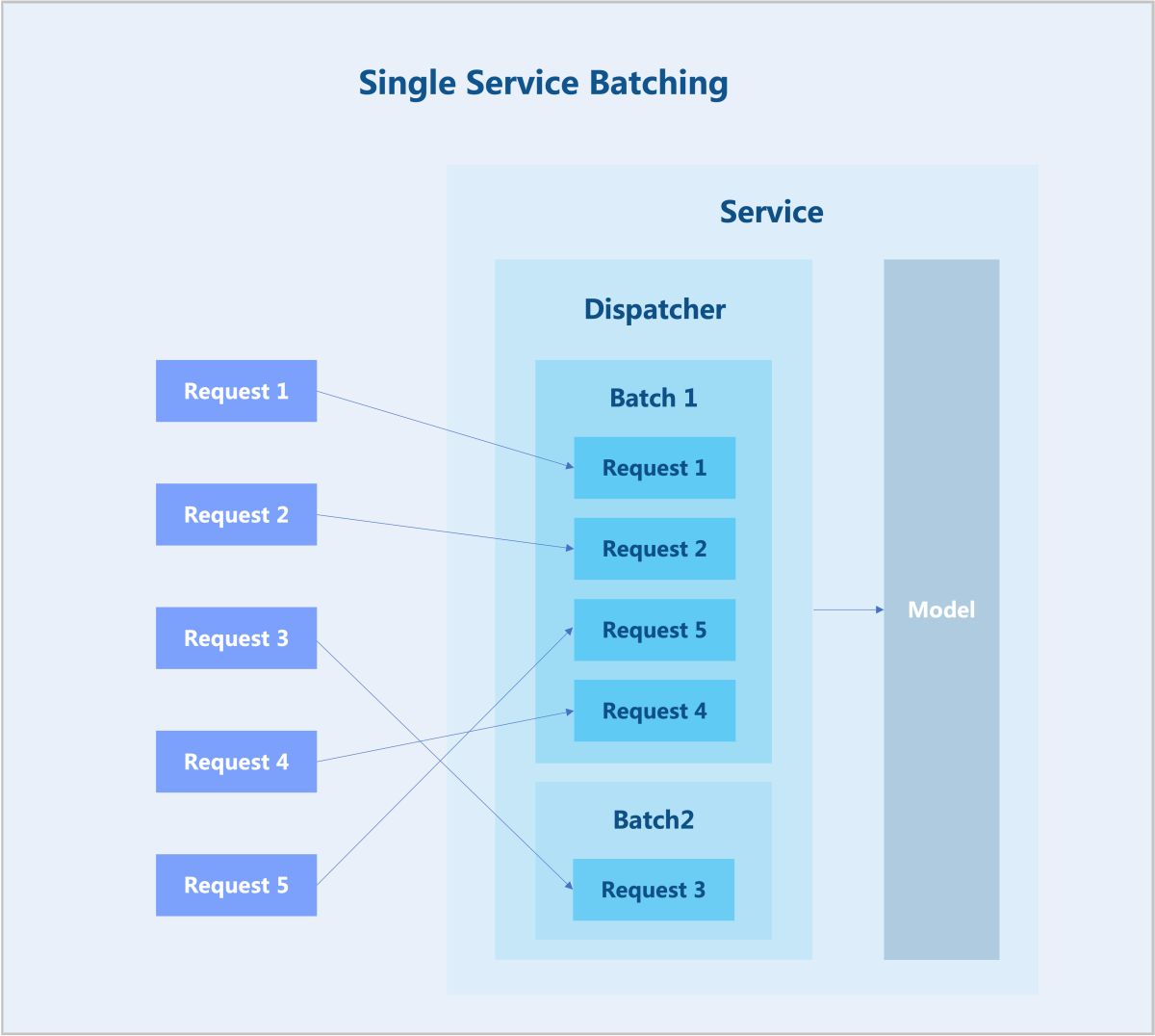
图1 Single Service Batching
在多服务场景中,亦能很好地处理跨服务带来的复杂性。支持基于服务的负载情况和延迟需求动态调整批量大小,确保在吞吐量和响应时间之间达到平衡。
如图2所示:
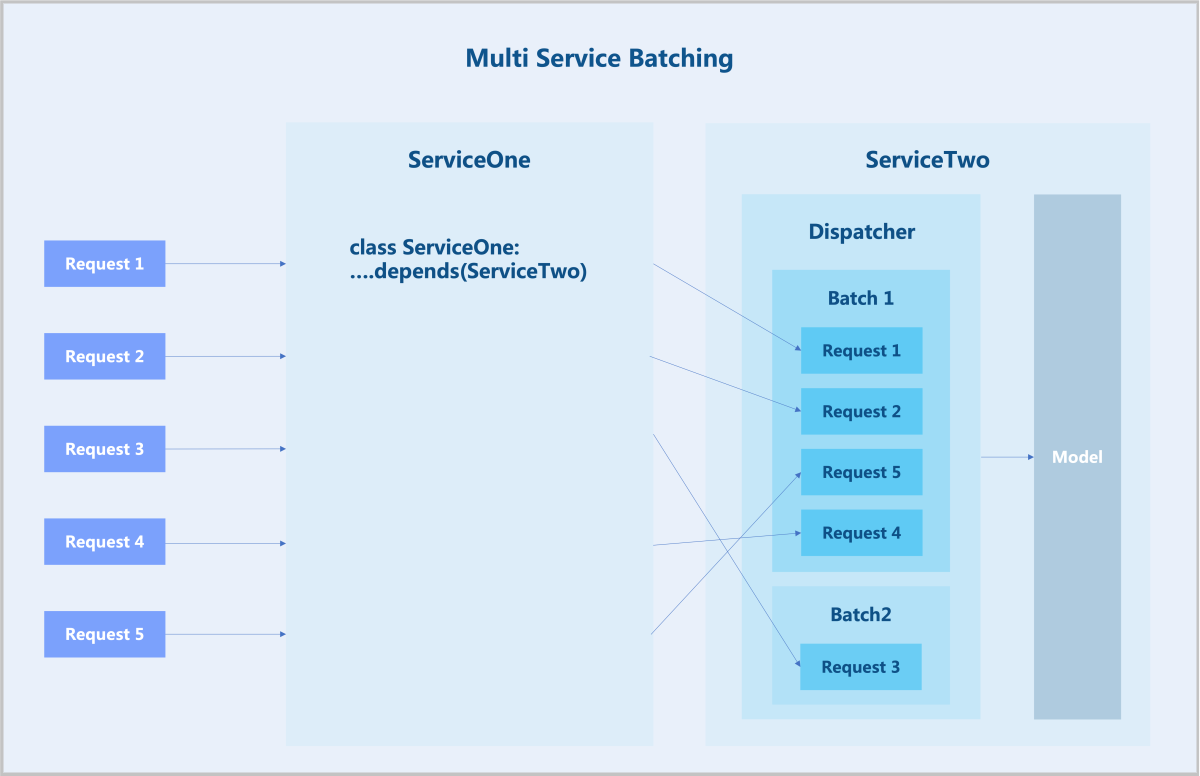
图2 Multi Service Batching
可见,负责运行模型推理的服务(ServiceTwo)从依赖服务(ServiceOne)收集请求,并根据最佳延迟形成批次。
自适应批量推理(Adaptive Batching)带来显著的性能和开发效率提升:
- 吞吐量提升:通过批量推理,一次性处理更多请求,减少重复操作。
- 降低延迟波动:动态调整批量大小,适配不同的负载场景,保证响应时间稳定。
- 无需手动配置:完全自动化,无需开发者额外干预。
模型服务化与自动化部署
提供一套简洁的模型服务化框架,支持从模型导出到生产环境部署的全流程自动化。其关键能力包括:
- 统一的模型打包格式:通过标准命令行工具或Python API,开发者可轻松将AI模型及其依赖打包为一个标准化的Bento包。
- 自动化部署到多种环境:支持将服务快速部署到Kubernetes、AWS Lambda、Docker等多种生产环境,无需复杂配置。
- 高性能模型运行时:针对不同深度学习框架(如TensorFlow、PyTorch、ONNX等)提供优化的运行,并确保推理性能最大化。
上述功能让开发者能够快速将模型上线,并确保其在生产环境中高效运行。