场景挑战与应对
- GPU算力如何灵活切分和高效利用:
- 在AI推理过程中,GPU通常是最昂贵的资源,但GPU利用率受限于模型加载时间、数据传输延迟和任务分配机制,可能造成算力浪费。
- 不同推理任务对GPU资源需求差异显著,如何动态切分和分配GPU资源以适应不同任务规模成为一大挑战。
- 海量模型与数据存储需求:
- AI推理通常涉及大规模的模型文件(GB级甚至TB级)以及海量的推理输入/输出数据。
- 传统文件系统在扩展到PB级别时成本高、可靠性差,无法满足需求。
- 高并发访问:
- 推理服务往往需要处理大量并发请求,要求存储系统支持高吞吐量和低延迟的文件访问。
- 模型加载、推理数据的读取和写入都可能成为性能瓶颈。
- 小文件操作性能问题:
- 推理任务中频繁涉及小文件(如推理配置、输入数据、日志等)的读写操作,而传统存储系统在处理小文件时效率低下。
ZStack AIOS支持丰富的GPU虚拟化技术,可在云主机、容器实例中直通或切分GPU算力,从而实现GPU在多客户端复用,有效避免使用国外技术的高昂成本,以及弥补国产GPU硬件层面不支持虚拟化和复用的不足。同时,ZStack AIOS支持集中监控海量GPU的运行状态,针对存在异常迹象的GPU可主动触发告警,提醒运维人员及时介入和处理;以及支持为多个企业账户分配可使用的GPU、存储等资源额度,实现高效的多租户管理。
- GPU切分与高效利用:
- 通过GPU虚拟化(dGPU管理、vGPU管理)和直通技术,将GPU资源切分为多个虚拟GPU单元,按需分配给不同推理任务。
- 在容器中,通过CUDA劫持技术灵活切分GPU资源,实现多容器间GPU的动态共享,提高硬件利用率。
- 通过CUDA API拦截转发技术,支持将NVIDIA物理GPU按需切分为细粒度的dGPU(动态GPU),供云主机灵活使用。无需整卡预切,按需动态加载与释放,打破固定等分限制,可有效避免大显存GPU独占浪费。同时无需额外License授权,显著降低运维成本。
- 无限扩展的存储能力:利用对象存储作为后端,实现PB级的存储扩展能力,轻松管理大规模模型和推理数据。
- 高性能的数据访问:通过多级缓存和分布式架构,显著提升模型加载速度和推理数据的读写效率,支持高并发访问。
- 小文件高效处理:优化小文件的存储和访问性能,保证推理任务中频繁的小文件操作不会影响整体性能。
算力利用最大化 (GPU虚拟化)
- GPU直通
支持将物理GPU卡直接映射到云主机的地址空间。在云主机中,使用原生设备驱动就可直接使用设备,达到近乎物理设备的性能。GPU被透传后由云主机独享,其它云主机无法共享使用该设备。
如图1所示: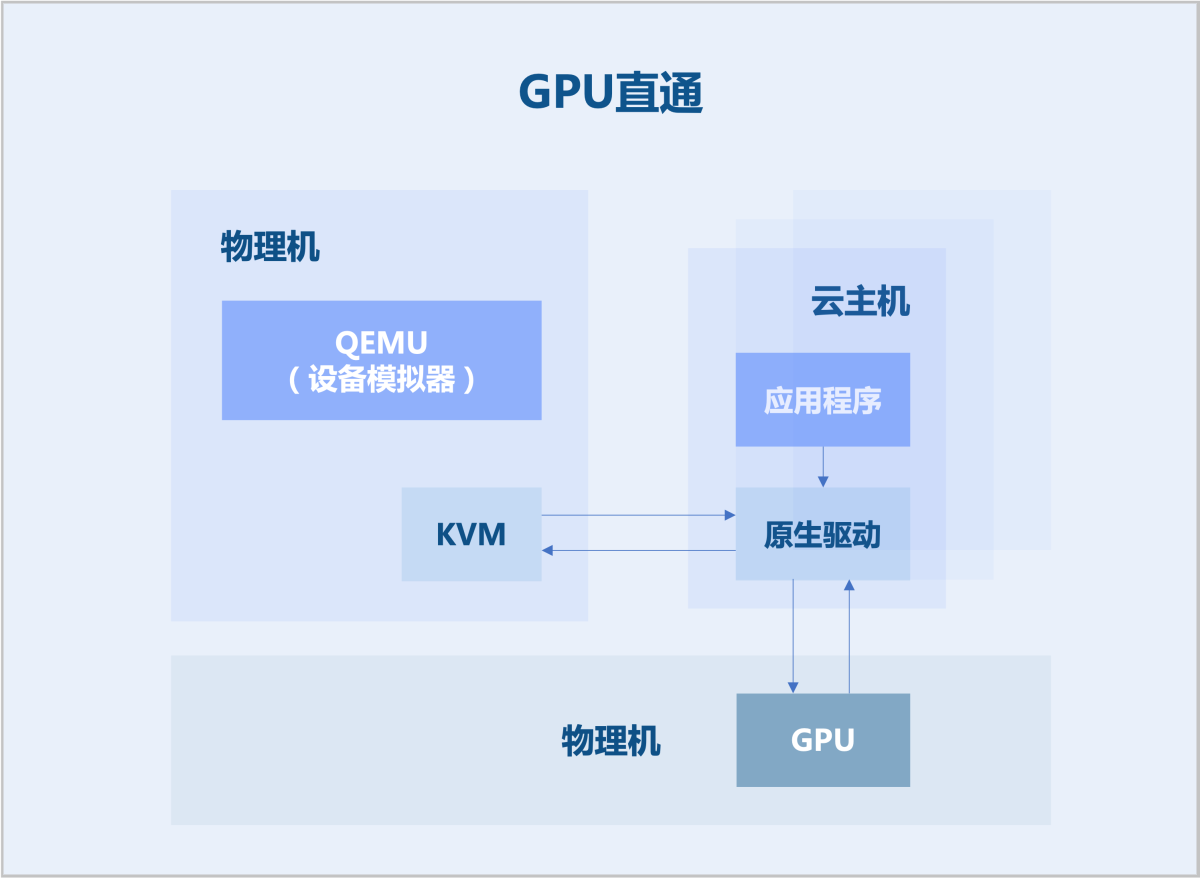
图1 GPU直通 - vGPU切分与直通
支持将物理GPU卡切割成更细粒度的vGPU,形成vGPU资源池,并支持将vGPU直接映射到云主机的地址空间。vGPU被透传后由云主机独享,其它云主机无法共享使用该设备。
如图2所示: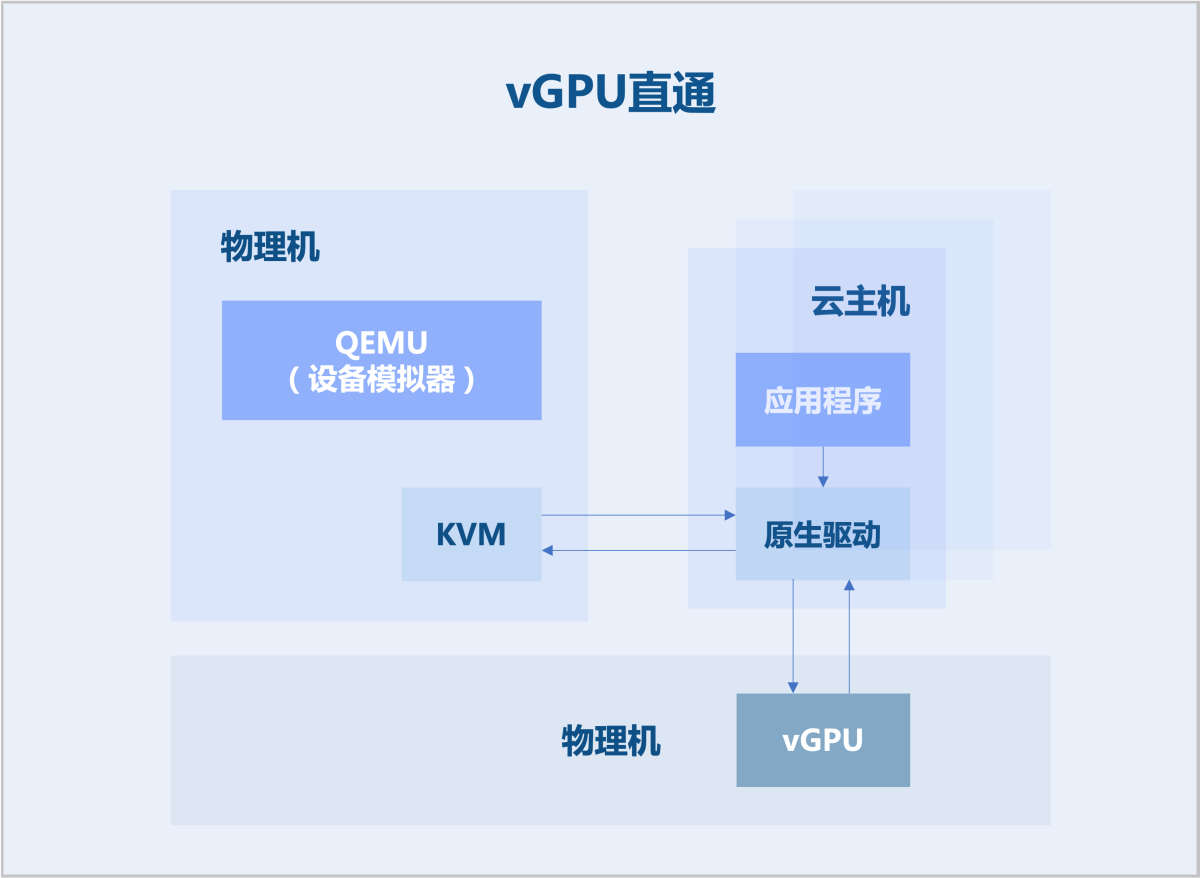
图2 vGPU直通 - 容器GPU显存切分(CUDA劫持技术)
主要使用软件层面的vCUDA方案,对原生CUDA驱动进行重写,然后挂载到Pod中进行替换,以及在CUDA驱动中对API进行拦截,从而实现资源隔离以及限制的效果。
- dGPU切分(CUDA API拦截转发技术)
通过在云主机内拦截CUDA API调用,将GPU操作请求转发至物理机侧的dGPU Worker进程代理执行,并利用ivshmem(物理机共享内存)实现云主机与物理机之间的零拷贝通信。dGPU Worker进程对每个dGPU实例实施显存硬隔离,并根据分配显存占物理卡总显存的比例自动计算算力限速,实现算力软隔离。物理GPU无需提前划分,dGPU Worker随云主机启动按需创建、关机按需销毁,显存实时归还资源池。
如图5所示: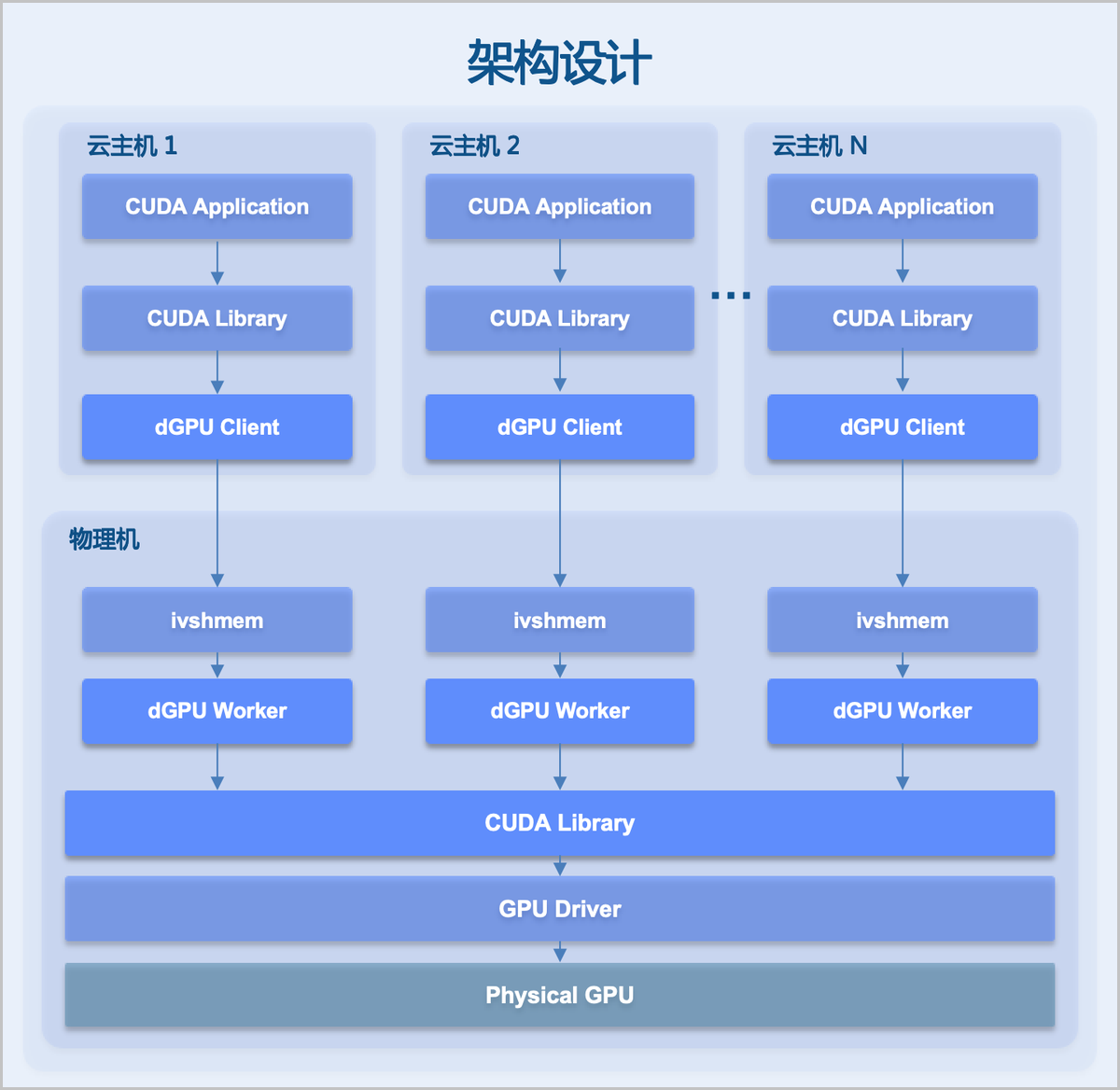
图5 架构设计
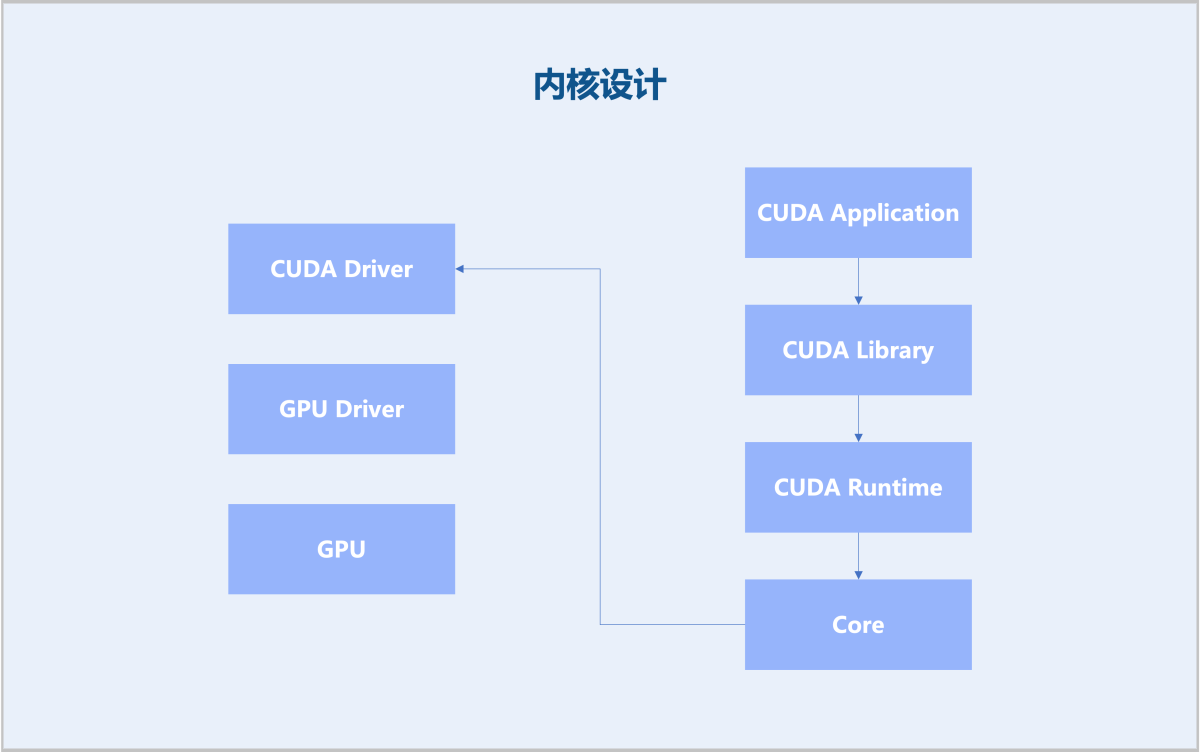
高性能缓存与优化 (ZDFS)
为满足AI推理场景对低延迟和高吞吐量的要求,ZStack AIOS采用ZDFS存储系统提供高效的缓存机制和性能优化策略。
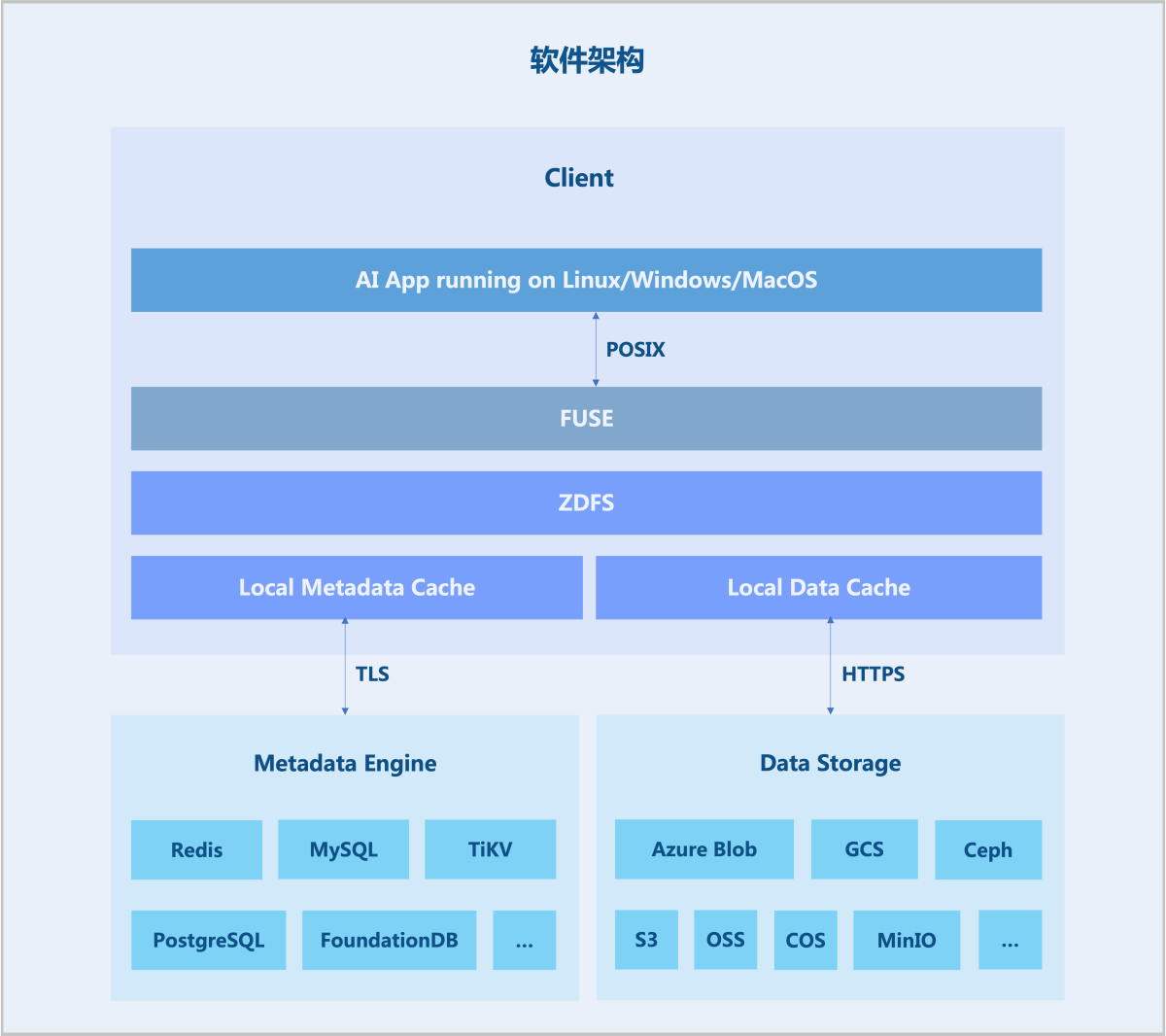
- 客户端(Client):
- 所有文件读写,以及碎片合并、回收站文件过期删除等后台任务,均在客户端中发生。客户端需要同时与对象存储和元数据引擎打交道。
- 客户端支持多种接入方式:通过FUSE、ZDFS文件系统能够以POSIX兼容方式挂载到服务器,将海量云端存储直接当做本地存储来使用。
- 数据存储(Data Storage):
- 文件会被切分上传至对象存储。
- 支持几乎所有的公有云对象存储。
- 支持OpenStack Swift、Ceph、MinIO等私有化对象存储。
- 元数据引擎(Metadata Engine):
- 用于存储文件元数据(metadata),包括:
- 常规文件系统的元数据:文件名、文件大小、权限信息、创建修改时间、目录结构、文件属性、符号链接、文件锁等。
- 文件数据的索引:文件的数据分配和引用计数、客户端会话等。
- 采用多引擎设计,目前已支持Redis、TiKV、MySQL/MariaDB、PostgreSQL、SQLite等作为元数据服务引擎,也将陆续实现更多元数据存储引擎。
- 用于存储文件元数据(metadata),包括:
- 多级缓存机制:
- 提供三个读写缓冲区:内核页缓存、客户端的内存缓存、客户端所在机器的本地缓存。
- 可实现:
- 本地缓存:将模型文件和常用数据缓存到本地磁盘或内存中,显著降低模型加载的延迟。
- 分布式缓存:在多个推理节点之间共享缓存,避免重复加载模型文件,提升资源利用率。
如图7所示: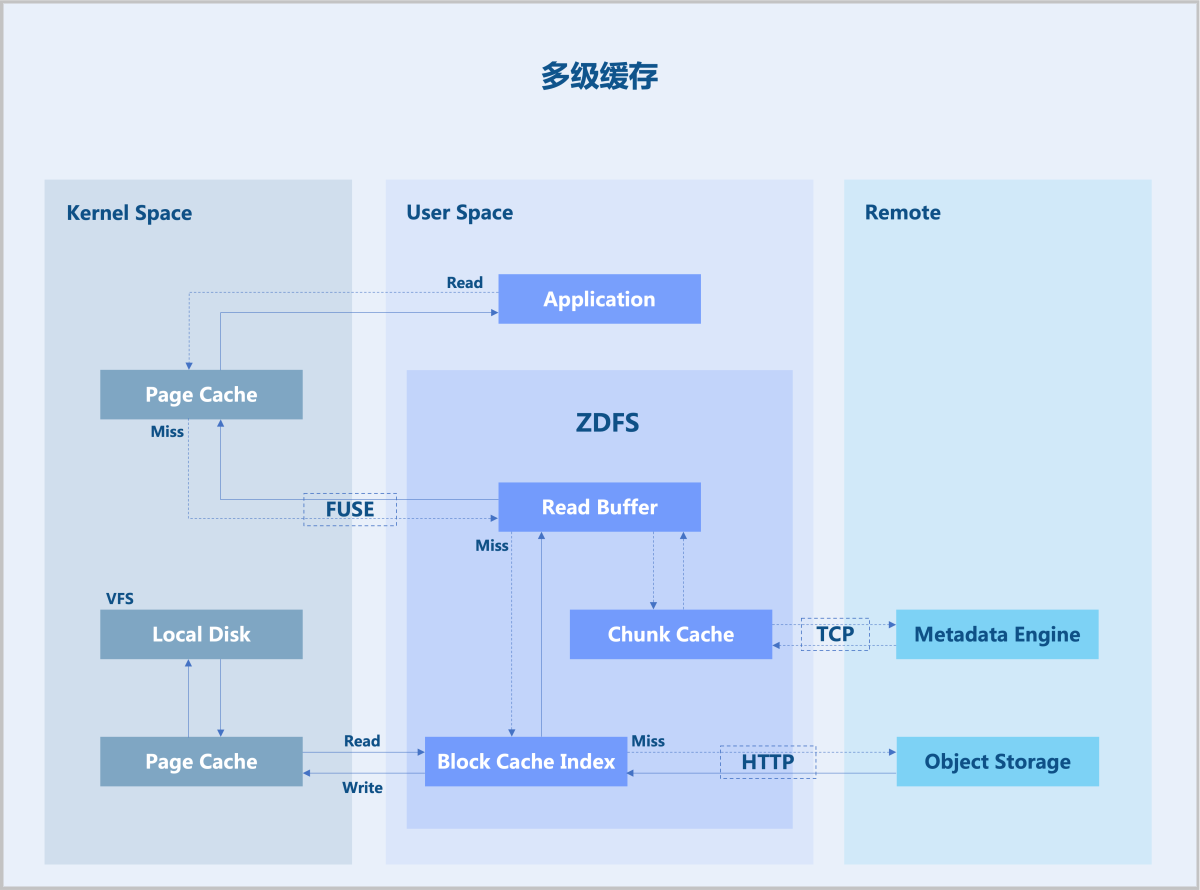
图7 多级缓存 可见,读请求会依次尝试内核分页缓存(Page Cache)、ZDFS进程的预读缓冲区(Read Buffer)、本地磁盘缓存(Block Cache Index),当缓存中没找到对应数据时才会从对象存储读取,并且会异步写入各级缓存保证下一次访问的性能。
- 小文件优化:
- AI推理场景中频繁的小文件操作(如模型配置文件、推理输入数据等)通过聚合写入和批量读取优化,保证小文件读写性能。
- 并行数据访问:
- 支持多线程并行加载模型文件,充分利用底层对象存储的带宽,提升推理服务的启动速度。
- 智能数据分层存储:
- 热数据(如当前推理任务的模型文件)优先存储于本地缓存或高速介质中,冷数据则存储在对象存储中,平衡性能和存储成本。