集群
概述
集群:一组物理机(计算节点)的逻辑集合。在数据中心中,一个集群一般对应了一个机架。
- 集群内所有物理机须拥有相同的操作系统。
- 集群内所有物理机须拥有相同的网络配置。
- 集群内所有物理机须能够访问相同的主存储。
- 集群需加载主存储、二层网络后,才可提供云主机服务。
- 集群的规模,也就是每个集群中可以包含物理机的最大数量,没有限制。
以下对集群与各个资源之间的关系进行说明。
集群 | 区域
支持多集群操作。可在一个区域内创建多个集群,新增的物理机可以按需添加到不同的集群之中。
集群 | 主存储和二层网络
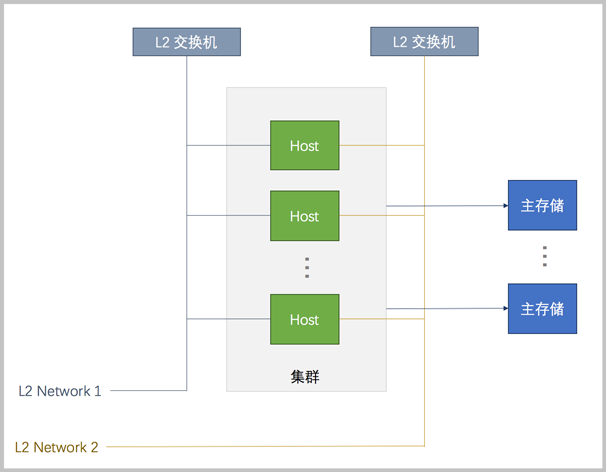
- 集群 | 主存储
- 一个主存储可以加载到多个集群。
- 一个集群可以加载多个主存储。目前支持的同类型主存储场景如下:
- 一个集群可以加载一个或多个本地主存储。
- 一个集群可以加载一个或多个NFS主存储。
- 一个集群可以加载一个或多个Shared Block主存储。
- 一个集群可以加载一个Shared Mount Point主存储。
- 一个集群只能加载一个Ceph主存储。
- 一个集群只能加载一个Vhost主存储。
- 一个集群只能加载一个CBD主存储。
- 一个集群只能加载一个AliyunNAS主存储,除此之外不能再加载新的存储。
- 一个集群只能加载一个AliyunEBS主存储,除此之外不能再加载新的存储。
目前支持的组合类型主存储场景如下:- 一个集群可以加载一个本地主存储和一个NFS主存储。
- 一个集群可以加载一个本地主存储和一个Shared Mount Point主存储。
- 一个集群可以加载多个本地主存储和多个Shared Block主存储。
- 一个集群可以加载一个Ceph主存储和最多三个本地存储。
- 一个集群可以加载一个Ceph主存储和一个Shared Block主存储。
- 一个集群可以加载一个Ceph主存储和多个Shared Block主存储。
- 一个集群可以加载多个NFS主存储和多个Shared Block主存储。
主存储与集群的依赖关系如表 1所示:主存储 集群 Local Storage 支持加载一个或多个本地存储 NFS 支持加载一个或多个NFS Shared Block 支持加载一个或多个Shared Block Shared Mount Point 支持加载一个Shared Mount Point Ceph 是加载到集群的Ceph,有且仅有一个 Vhost 支持加载一个Vhost CBD 支持加载一个CBD AliyunNAS 是加载到集群的AliyunNAS,有且仅有一个 AliyunEBS 是加载到集群的AliyunEBS,有且仅有一个 Local Storage + NFS 支持加载1个Local Storage + 1个NFS Local Storage + SMP 支持加载1个Local Storage + 1个Shared Mount Point Local Storage + Shared Block 支持加载多个Local Storage + 多个Shared Block Ceph + LocalStorage 支持加载1个Ceph + 最多3个LocalStorage Ceph + Shared Block - 支持加载1个Ceph + 1个Shared Block
- 支持加载1个Ceph + 多个Shared Block
NFS + Shared Block 支持加载多个NFS + 多个Shared Block - 集群加载多个本地存储时,务必在添加物理机以及添加主存储之前,提前在物理机对应URL上做好分区,确保每个本地存储部署在独占的逻辑卷或物理磁盘上。
- 主存储可以被所在集群中的所有物理机访问。
- 如果数据中心的网络拓扑发生改变导致主存储不能被集群中的物理机继续访问,主存储可以从集群卸载。
- 集群 | 二层网络
- 一个集群可以加载一个或多个二层网络;一个二层网络可以加载到多个集群。
- 集群可以加载VXLAN Pool,VXLAN Pool下不同的VNI可用于创建不同的VxlanNetwork。
- 一个网卡只能创建一个NoVlanNetwork。
- 对于VlanNetwork,不同VLAN ID代表不同的二层网络。
- 如果数据中心的网络拓扑发生改变导致集群中的物理机不再在二层网络所代表的物理二层广播域中,二层网络也可以从集群卸载。
集群 | 镜像服务器
集群与镜像服务器没有直接依赖关系,一个镜像服务器可以为多个集群提供服务。
| PS\BS | ImageStore | Ceph |
| Local Storage | ○ | × |
| NFS | ○ | × |
| Shared Mount Point | ○ | × |
| Ceph | ○ | ○ |
| Shared Block | ○ | × |
| Vhost | ○ | × |
| CBD | ○ | × |
- 当主存储为LocalStorage、NFS、Shared Mount Point类型时,镜像服务器的默认类型为ImageStore。
- 当主存储为NFS或Shared Mount Point类型时,可将相应共享目录手动加载到相应镜像服务器的本地目录上,从而使主存储和镜像服务器均能使用网络共享存储方式。
- 当主存储为Ceph类型时,镜像服务器可以使用同一个Ceph集群作为镜像服务器,也可以使用ImageStore类型的镜像服务器。
- 当主存储为Shared Block类型时,镜像服务器的默认类型为ImageStore。
- 当主存储为AliyunNAS类型时,镜像服务器的默认ImageStore。
- 当主存储为AliyunEBS类型时,镜像服务器的默认类型为AliyunEBS。
创建集群
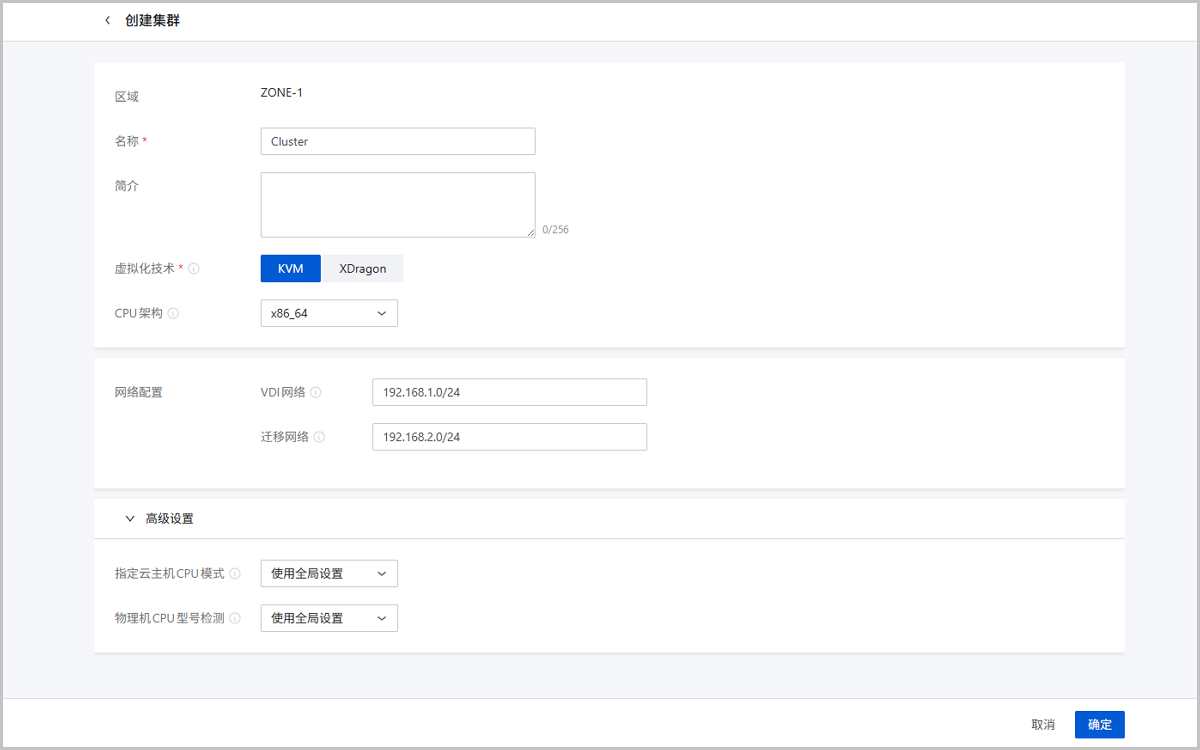
在ZStack Cube 旗舰版主菜单,点击,进入集群界面。点击创建集群,弹出创建集群界面。
- 区域:显示当前所在区域
- 名称:设置集群名称。命名规则:长度限制1~128字符,输入内容只能包含中文汉字、英文字母、数字、空格和以下7种英文字符
- _ . ( ) : +且不支持以空格开头或结尾 - 简介:可选项,备注相关信息
- 虚拟化技术:可选项,选择集群的Hypervisor类型,包括:KVM、XDragon
- 若选择KVM类型,集群内所有物理机需采用KVM虚拟化技术。
- 若选择XDragon类型,集群内所有物理机需采用阿里云神龙架构。
- CPU架构:设置集群内物理机的CPU架构,包括:x86_64、aarch64、mips64el、loongarch64Note:
- 若留空则在添加第一台物理机时指定为物理机的CPU架构。
- CPU架构一旦设置,无法修改,请按照实际情况进行设置。
- 网络配置:为集群配置专用的业务场景网络
- VDI网络:可选项,VDI场景单独使用的网络,需填写VDI网络CIDR
- 若用户已部署VDI场景单独使用的网络,可直接将其添加到云平台。
- 使用单独的VDI网络,可避免网络拥塞,提高传输效率。
- 若不设置,VDI将默认使用管理网络。
- 迁移网络:可选项,迁移云主机单独使用的网络,需填写迁移网络CIDR
- 若用户已部署迁移云主机单独使用的网络,可直接将其添加到云平台。
- 使用单独的迁移网络,可避免网络拥塞,提高传输效率。
- 若不设置,迁移云主机将默认使用管理网络。
- VDI网络:可选项,VDI场景单独使用的网络,需填写VDI网络CIDR
- 高级设置:为集群配置高级参数。仅KVM集群支持高级设置
- 指定云主机CPU型号:可选项,指定集群内云主机CPU型号
集群CPU架构 集群内云主机CPU型号 全局设置云主机CPU模式 说明 注意 x86_64 使用全局设置(默认) - 当前集群内云主机CPU型号由全局设置云主机CPU模式决定。
none(默认) 云平台全局范围内云主机CPU型号由QEMU模拟而成,较小范围内继承所在物理机CPU的特性,迁移场景时推荐设置该模式。 - host-passthrough模式支持云主机嵌套虚拟化,但该模式可能导致云主机在不同型号CPU的物理机之间迁移失败,还可能导致从云主机内部和从云主机所在物理机查看云主机CPU使用率数值不一致。
- 若云主机已单独设置CPU模式,此集群设置将不对该云主机生效。
- 若集群已指定云主机CPU型号,全局设置云主机CPU模式将不对该集群生效。
- 修改CPU模式后,必须重启云主机生效。
host-model 云平台全局范围内云主机CPU型号与物理机CPU型号接近或一致,例如:都显示为Haswell Intel CPU。相比none模式,该模式下,云主机可继承所在物理机CPU较多特性,可用于迁移场景。 host-passthrough 云平台全局范围内云主机CPU型号与所在物理机CPU型号一致。同时,云主机CPU特性与物理机CPU特性一致,例如:都支持扩展页表、大页内存以及虚拟化等。相比none、host-model和自定义 模式,该模式继承的物理机CPU特性最多,适用于对云主机功能有较高要求的业务场景。 自定义(某一特定CPU型号) 云平台全局范围内云主机将配置为该CPU型号。自定义CPU型号后,云主机可能具备与之前自定义型号不同的CPU特性。 none N/A 当前集群内云主机CPU型号由QEMU模拟而成,较小范围内继承所在物理机CPU的特性,迁移场景时推荐设置该模式。 host-model N/A 当前集群内云主机CPU型号与物理机CPU型号接近或一致,例如:都显示为Haswell Intel CPU。相比none模式,该模式下,云主机可继承所在物理机CPU较多特性,可用于迁移场景。 host-passthrough N/A 当前集群内云主机CPU型号与所在物理机CPU型号一致。同时,云主机CPU特性与物理机CPU特性一致,例如:都支持扩展页表、大页内存以及虚拟化等。相比none、host-model和自定义 模式,该模式继承的物理机CPU特性最多,适用于对云主机功能有较高要求的业务场景。 自定义(某一特定CPU型号) N/A 当前集群内云主机将配置为该CPU型号。自定义CPU型号后,云主机可能具备与之前自定义型号不同的CPU特性。 aarch64· host-passthrough(默认) N/A 当前集群内云主机CPU型号与所在物理机CPU型号一致。同时,云主机CPU特性与物理机CPU特性一致。相比host-model和自定义模式,该模式继承的物理机CPU特性最多,适用于对云主机功能有较高要求的业务场景。 host-model N/A 当前集群内云主机CPU型号与物理机CPU型号接近或一致。该模式下,云主机可继承所在物理机CPU较多特性,可用于迁移场景。 自定义(某一特定CPU型号) N/A 当前集群内云主机将配置为该CPU型号。自定义CPU型号后,云主机可能具备与之前自定义型号不同的CPU特性。 mips64el 某一特定CPU型号 N/A 当前集群内云主机将统一配置为该CPU型号。 loongarch64 某一特定CPU型号 N/A 当前集群内云主机将统一配置为该CPU型号。 - 物理机CPU型号设置:可选项,设置集群内物理机CPU型号检测机制
集群内物理机CPU型号检测机制 全局设置物理机CPU型号检测 说明 注意 使用全局设置(默认) - 集群内物理机CPU型号由全局设置物理机CPU型号检测决定。
false(默认) 云平台全局范围内,热迁移云主机或添加物理机时,系统将不检测源/目标物理机CPU型号的一致性。 集群内物理机CPU型号的统一,从前提上能确保云主机迁移成功的可能性。 true 云平台全局范围内,热迁移云主机或添加物理机时,系统将检测源/目标物理机CPU型号的一致性,若不一致,则不允许热迁移云主机或添加物理机操作。 检查 N/A 热迁移云主机或添加物理机时,系统将检查源物理机与当前集群内物理机CPU型号的一致性,若不一致,则不允许热迁移云主机或添加物理机操作。 不检查 N/A 热迁移云主机或添加物理机时,系统将不检查源物理机与当前集群内物理机CPU型号的一致性。
- 指定云主机CPU型号:可选项,指定集群内云主机CPU型号
管理集群
在ZStack Cube 旗舰版主菜单,点击,进入集群界面。
| 操作 | 描述 |
|---|---|
| 创建集群 | 在当前区域内创建一个新的集群。 |
| 编辑集群 | 修改集群的名称与简介。 |
| 启用集群 | 将处于停用状态的集群启用。 |
| 停用集群 | 将处于启用状态的集群停用。 Note:
|
| 加载二层网络 | 将二层网络加载到集群。 |
| 卸载二层网络 | 将二层网络从集群卸载。 Note: 卸载二层网络后,相应的云主机网卡将被卸载,请谨慎操作。 |
| 加载主存储 | 将主存储加载到集群。 |
| 卸载主存储 | 将主存储从集群卸载。 Note: 将主存储从集群卸载,需要注意以下情况:
|
| 删除集群 | 删除选中的集群。 Note:
|
集群详情
集群关联资源
- 云主机:
该子页面展示了当前集群内所有云主机列表。主要显示云主机名称、控制台、启用状态、CPU、内存、IPv4地址、IPv6地址、集群等信息。点击目标云主机旁的更多操作,可对云主机进行各种操作。
- 物理机:
该子页面展示了当前集群内所有物理机列表。主要显示物理机名称、物理机IP地址、虚拟化技术类型、启用状态等信息。点击目标物理机旁的更多操作,可对物理机进行各种操作。
- 主存储:
该子页面展示了加载到当前集群的主存储列表。主要显示主存储名称、主存储类型、挂载路径、容量使用率、启用状态、就绪状态等信息。点击目标主存储旁的更多操作,可对主存储进行卸载操作。
- iSCSI存储:
该子页面展示了加载到当前集群的iSCSI存储列表。主要显示iSCSI存储名称、IP地址、端口号、启用状态等信息。点击目标iSCSI存储旁的更多操作,可对iSCSI进行卸载操作。
- 二层网络:
该子页面展示了加载到当前集群的二层网络列表。主要显示二层网络名称、网卡、二层网络类型、VNI等信息。点击目标二层网络旁的更多操作,可对二层网络进行卸载操作。
- 物理网卡:该子页面展示了当前集群内所有物理机的物理网卡列表。主要显示物理网卡名称、网卡类型、所在物理机、就绪状态、速率、虚拟化状态、虚拟网卡可用量/总量等信息。点击目标物理网卡旁的更多操作,可对物理网卡进行更多操作,例如表 1:
操作 描述 SR-IOV切割 将物理网卡虚拟化切割成多张虚拟网卡,直接分配给云主机使用。 Note: SR-IOV切割物理网卡需要满足以下条件:- 确保该物理网卡支持SR-IOV切割。
- 确保该物理网卡所在物理机BIOS已开启Intel VT-d / AMD IOMMU功能和SR-IOV功能。
- 确保该物理网卡所在物理机IOMMU就绪状态为可用。
SR-IOV还原 将虚拟网卡还原成物理网卡。 Note: 若当前物理网卡切割成的虚拟网卡正在被云主机使用,SR-IOV还原将同时从云主机卸载相关网卡,请谨慎操作。 - 物理GPU设备:该子页面展示了当前集群内所有物理机已加载的物理GPU设备列表。主要显示设备名、规格信息、设备地址、类型、所在物理机、启用状态、就绪状态、虚拟化状态、云主机等信息。点击目标物理GPU设备旁的更多操作,可对物理GPU设备进行更多操作,例如表 2:
操作 描述 虚拟化切割 对所选设备进行虚拟化切割,可将未用于透传的物理GPU设备切割成若干固定规格的vGPU。 虚拟化还原 对所选设备进行虚拟化还原,将vGPU还原成物理GPU。 - vGPU设备:
该子页面展示了当前集群内所有物理机已加载的vGPU设备列表。主要显示vGPU设备名称、规格信息、设备地址、所在物理机、对应物理GPU设备名,启用状态、就绪状态、云主机等信息。点击目标vGPU设备旁的更多操作,可对vGPU设备进行各种操作。
- USB设备:该子页面展示了当前主存储已加载USB设备的列表。主要显示USB设备名、所在物理机、加载方式、生产商、类型、启用状态、USB版本、已加载到的云主机等信息。点击目标USB设备旁的更多操作,可对USB设备进行更多操作,例如表 3:
操作 描述 修改设备名 修改该设备的设备名称。 启用 启用该USB设备。 停用 停用该USB设备。 加载云主机 将该设备加载至指定的云主机。 卸载云主机 将该设备从指定云主机卸载。 - 其他设备:
该子页面展示了当前集群内所有物理机已加载的其他设备列表。主要显示设备名称、虚拟容量使用率、物理容量使用率、虚拟化技术类型、启用状态、就绪状态等信息。点击目标设备旁的更多操作,可对该设备进行更多操作,例如表 4:
操作 描述 启用 启用该设备。 停用 停用该设备。
动态资源调度
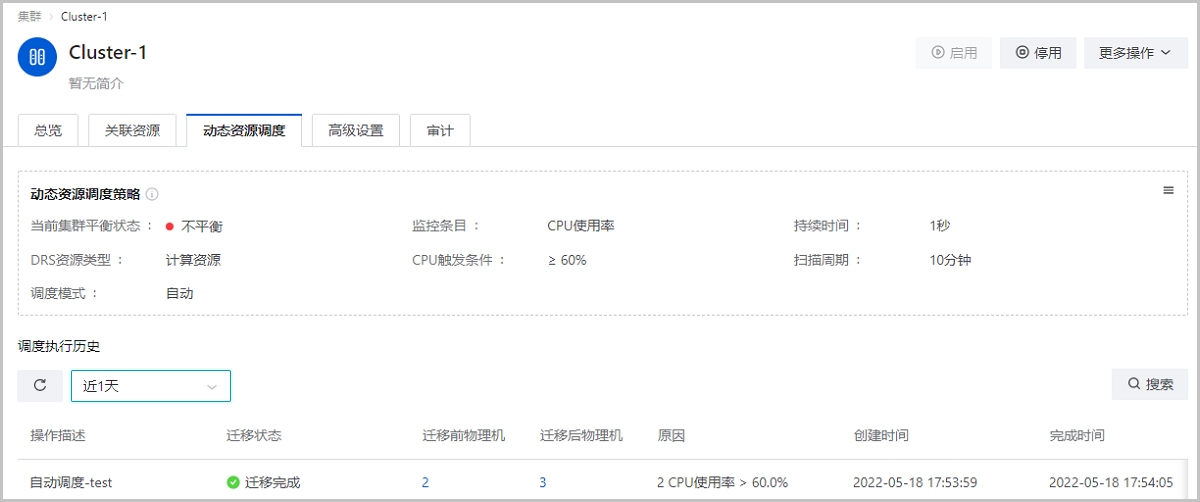
动态资源调度(Distributed Resource Scheduler,简称DRS):以集群为单位监控物理机CPU或内存负载情况,根据配置的调度策略,动态调整物理机上运行的云主机业务。
云平台支持手动和自动两种调度策略:手动调度策略提供调度建议,用户可按照调度建议手动迁移云主机。自动调度策略,由系统根据调度算法自动执行资源调度。两种调度策略均可平衡集群负载,且有效提高云平台稳定性。
- 打开动态资源调度开关。
- 配置动态资源调度策略。
- 执行动态资源调度相关操作。
打开动态资源调度开关
- 集群内仅存在Ceph、Shared Block类型的主存储。
- 集群内所有物理机CPU型号一致。
- 若动态资源调度运行过程添加Ceph、Shared Block以外的主存储或添加CPU型号不一致的物理机,将导致动态资源调度无法正常工作。
- 动态资源调度功能关闭后,继续保留调度策略相关配置,重新打开即可生效,支持点击修改配置按钮重新配置调度策略。
配置动态资源调度策略
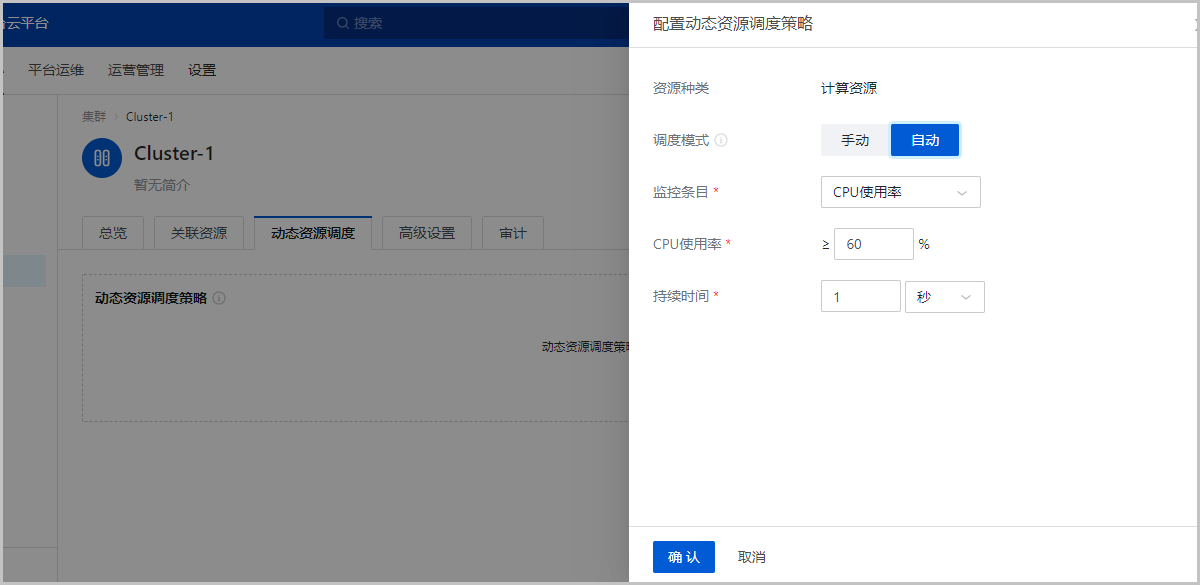
启用动态资源调度功能后,在动态资源调度页面,点击修改配置按钮,跳转到配置动态资源调度策略页面。
- 资源种类:默认为计算资源,暂不支持修改
- 调度模式:支持手动和自动两种调度模式:
- 手动调度:集群内物理机CPU使用率或内存使用率达到指定阈值后,用户手动根据调度建议执行资源调度。
- 自动调度:集群内物理机CPU使用率或内存使用率达到指定阈值后,系统根据调度算法自动执行资源调度。
- 监控条目:选择物理机监控条目,包括:CPU使用率、内存使用率、CPU或内存使用率
- CPU使用率:自定义CPU使用率监控条目触发条件
- 内存使用率:自定义内存使用率监控条目触发条件
- 持续时间:自定义阈值持续时间,单位包括:秒、分钟、小时
执行动态资源调度相关操作
- 平衡状态扫描:手动扫描集群平衡状态。Note:
- 系统基于默认扫描周期(默认10分钟)自动扫描集群平衡状态。
- 用户可自行设置扫描周期。设置方法:
进入,设置DRS集群扫描间隔即可,默认为600秒(即:10分钟)。
- 修改配置:修改动态资源调度策略相关配置,支持修改监控条目、触发条件和持续时间。
- 执行调度:按照调度建议,将云主机迁移至推荐的物理机,平衡集群负载。Note:
- 仅当设置为手动资源调度策略时支持该操作。
- 执行资源调度支持设置云主机迁移并发度,仅适用动态资源调度场景。设置方法:
进入,设置DRS云主机迁移并发度即可,默认为1,表示同一时刻允许云主机从当前所在物理机迁移至建议目标物理机的最大数量为1台。
- 查看执行历史:查看调度执行历史、执行结果、执行时间等信息,默认查看近7天数据。支持自定义时间段查看执行历史;支持按云主机UUID搜索执行历史。
集群高级设置
| 名称 | 简介 | 默认值 | 说明 |
|---|---|---|---|
| CPU超分率 |
|
10 |
|
| 内存超分率 |
|
1 |
|
| 物理机保留内存 | 用于设置集群内所有KVM物理机上保留的内存容量。 | 8GB |
|
| 集群大页开关 | 用于设置集群大页功能是否启用。 | false |
|
| 云主机Hyper-V开关 | 云主机Hyper-V模拟的开启或关闭。 | false | 若云主机已单独设置该选项,此集群设置将不对该云主机生效。 |
| 隐藏KVM虚拟化标记 | 云主机KVM虚拟化标记的开启或关闭。 | false | 若为true,则会在新启动云主机定义XML中对<kvm>插入<hidden
state='on'>,若为false则不会。 Note: NVIDIA显卡集群需启用该开关。 |
| 动态资源调度开关 | 动态资源调度功能是否启用。 | KVM集群默认为true;非KVM集群默认为false |
|
| Zero Copy开关 | 是否开启集群Zero Copy开关。 | false | 开启后将减少数据在内核态和用户态之间的拷贝次数,降低CPU占用时间,提升虚拟网卡性能。 Note: 可通过在物理机终端执行 cat
/sys/module/vhost_net/parameters/experimental_zcopytx命令验证该设置当前的状态:
|
| 网卡多队列优化开关 | 用于设置是否开启云主机网卡多队列优化。 | true | 开启后,系统将在云主机首次启动时,根据Linux云主机的CPU数量对其网卡多队列数量进行自动优化(最多12个队列),提升云主机性能。 |
| 网卡多队列数目 | 用于设置Virtio类型的网卡流量分配给多个CPU时的队列数目。 | 1 |
|
| 云主机Hypervisor | 用于设置是否开启云主机CPU虚拟化 (hypervisor) 标记 | true |
|
| 资源绑定策略 | 设置集群下云主机、路由器和当前集群的绑定程度,及跨集群迁移限制。仅对已开启集群绑定的资源生效 | 弱绑定 |
Note: 如资源未开启集群绑定,该设置对该资源不生效。
|
| 云盘多队列配置 | 为本地存储、NFS、Vhost、Ceph、SharedBlock以及AliyunEBS主存储中的云盘设置队列数,用于提高数据传输效率。 | false | 设置云盘队列数量,有效范围:1~128.
|