最大上下文长度是推理服务在一次推理过程中能够接受和处理的最大Token数量,该数量为输入 (Prompt) 和输出 (Completion) 的Token总和。
最大上下文长度影响推理服务的以下表现,请合理设置:
- 长文本处理:上下文长度决定推理服务可处理的文本总长度。较大的上下文长度能更好支持长文档分析、长代码理解、长内容输出等任务。
- 多轮对话:上下文长度决定推理服务保留的对话历史长度,影响对话连贯性和上下文理解能力。
- 资源占用:上下文长度越大,推理过程中所需的显存越多。
- 推理性能:上下文越长,每次推理的计算量越大,可能导致响应延迟增加、吞吐量下降。
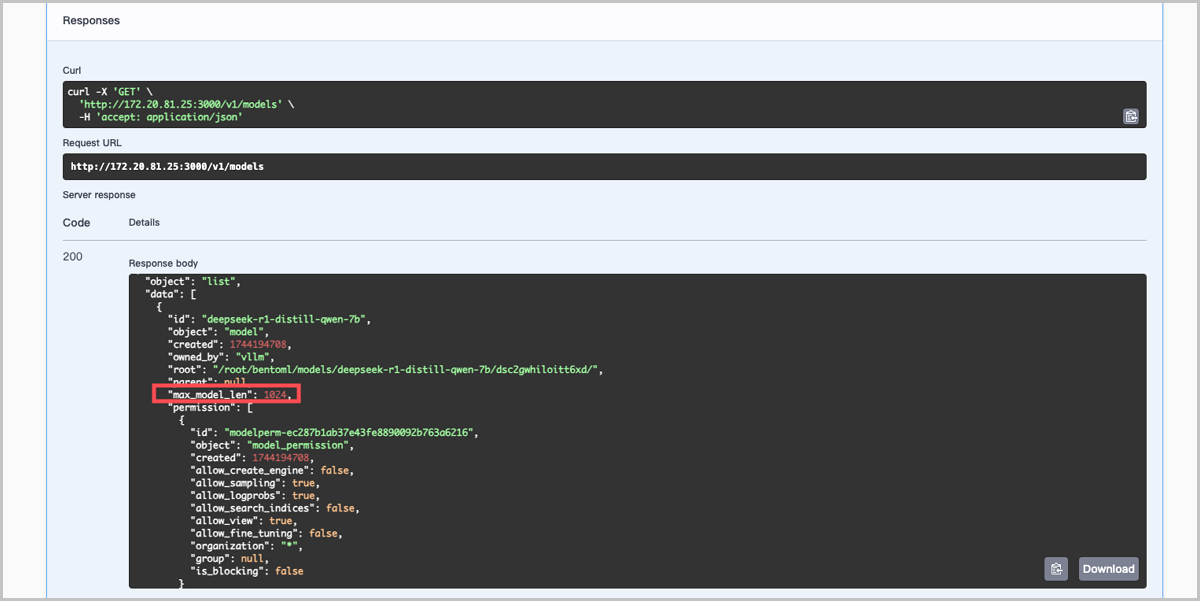
本场景假定某用户需部署系统模型DeepSeek-R1-Distill-Qwen-7B,选用vLLM-0.8.5推理模板,设置最大上下文长度为1K (1024 Toekn)。
-
通过环境变量设置最大上下文长度
ZStack AIOS支持在推理服务创建过程中或创建完成后,通过环境变量设置最大上下文长度。
- 创建过程中设置
在ZStack AIOS主菜单,点击,进入模型仓库界面。找到并点击需部署的模型,在右侧详情页,点击创建推理服务。
注意以下参数的设置,环境变量和启动变量设置其一即可:- 模型:显示部署的模型名称,本场景为DeepSeek-R1-Distill-Qwen-7B
- 选择推理模板:选择推理模板,本场景使用DeepSeek-R1-Distill-Qwen-7B的默认推理模板vLLM-0.8.5
- 环境变量:点击添加环境变量
- key:输入控制最大上下文长度的参数名。不同推理框架对应的该参数名可能不同,本场景输入MAX_MODEL_LEN
- value:输入最大上下文长度值,单位为Token,本场景设置为1024
- 启动变量:点击添加启动变量
- key:输入控制最大上下文长度的参数名。不同推理框架对应的该参数名可能不同,本场景输入max-model-len
- value:输入最大上下文长度值,单位为Token,本场景设置为1024
说明: 推理服务需要的显存资源受模型参数量、服务并发数量、量化级别、上下文长度等要素影响,请根据当前显存资源合理设置,避免服务创建失败。配置完成后,点击确定,开始创建推理服务。
如图1所示: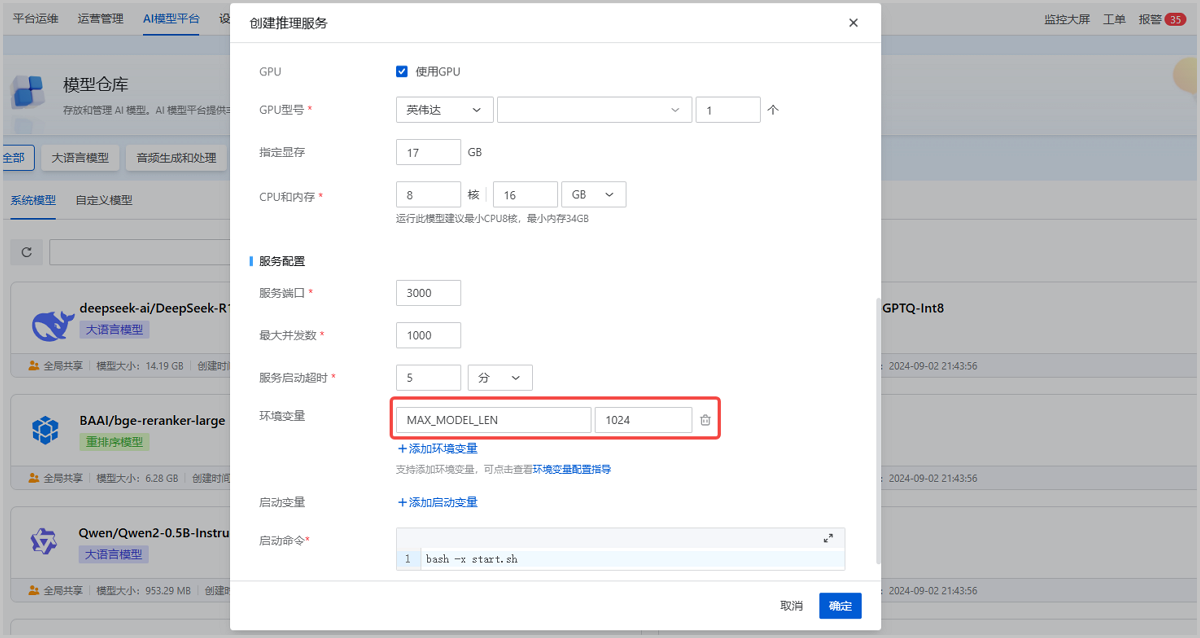
图1 创建推理服务并设置最大上下文长度 - 创建完成后设置
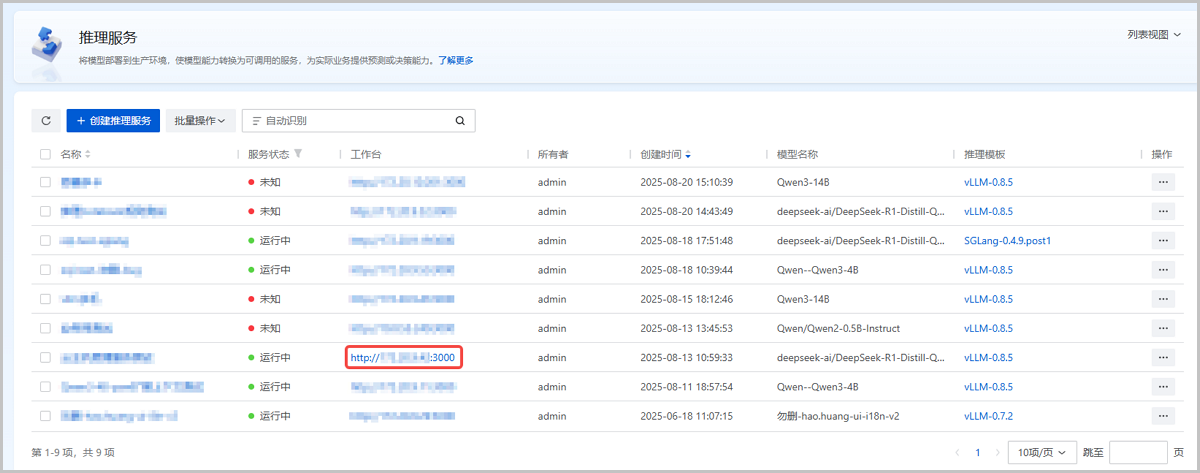
- 在ZStack AIOS主菜单,点击,进入推理服务界面。找到已部署的推理服务,点击。在修改服务配置界面,添加或修改最大上下文长度对应的环境变量/启动变量。如图2所示:
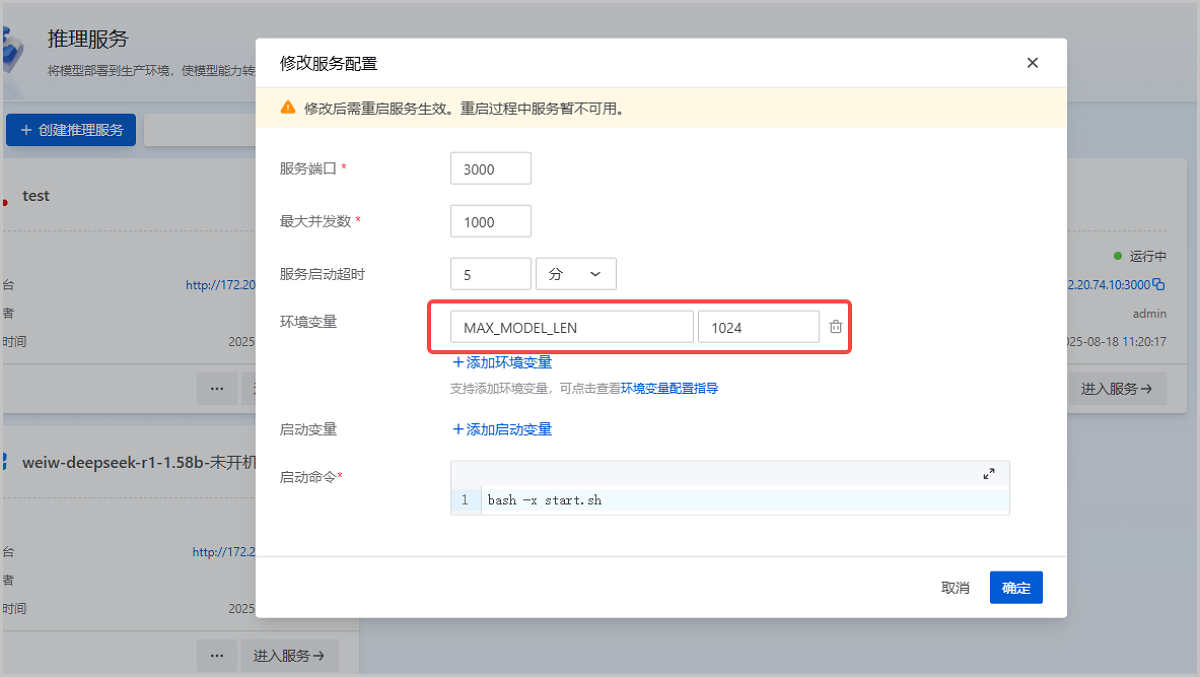
图2 为已创建推理服务修改最大上下文长度 - 重启推理服务,使修改生效。
- 在ZStack AIOS主菜单,点击,进入推理服务界面。找到已部署的推理服务,点击。在修改服务配置界面,添加或修改最大上下文长度对应的环境变量/启动变量。
- 创建过程中设置
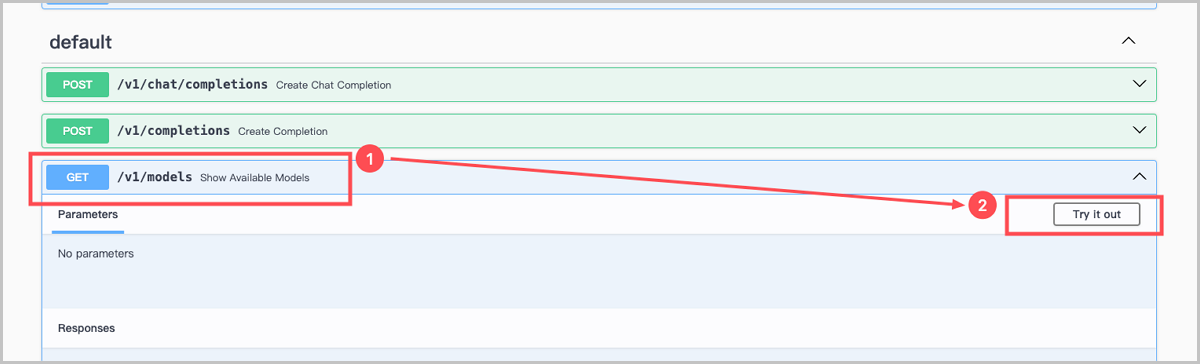
- 验证最大上下文长度是否生效