多机多卡推理服务指部署多台实例并配置多个GPU设备,用于运行推理服务。该部署模式可解决单实例、单GPU在大规模推理场景下可能出现的显存不足和计算瓶颈问题,提供更高效的推理服务。
说明: 部署多机多卡推理服务,需确保使用的推理模板和GPU设备支持。
- 推理模板对多机推理的支持情况详见推理模板
- GPU设备对多机多卡推理的支持情况详见GPU设备管理-推理部署
本场景假定某用户希望使用vLLM-0.8.5推理模板部署DeepSeek-R1-Distill-Qwen-32B,使用多云主机部署模式,加载NVIDIA RTX 3090 GPU设备。
本节将以上述场景为例,详细介绍部署多级多卡推理服务的方法,主要包括以下步骤:
- 添加自定义模型
- 创建推理服务
说明: 开始前,请确保已准备好对应的GPU设备并安装到物理机。
-
添加自定义模型
本场景使用非系统模型,部署前,需先将模型添加到ZStack AIOS在ZStack AIOS主菜单,点击,进入自定义模型界面,点击添加模型,弹出添加模型,可参考以下示例输入相应内容:
- 名称:设置模型名称
- 简介:可选项,可留空不填
- 来源:本场景以Hugging Face为例介绍,用户也可通过其他方式上传
- Model ID:输入Hugging Face中,DeepSeek-R1-Distill-Qwen-32B模型的Model ID,详情可参考添加模型-从Hugging Face导入
- Token:输入Hugging Face Access Token,详情可参考添加模型-从Hugging Face导入
- 类型:选择模型类型,本场景选择大语言模型
- 默认推理模板:选择默认推理模板,本场景选择vLLM-0.8.5
设置完成后,点击确定,开始添加模型。如图1所示: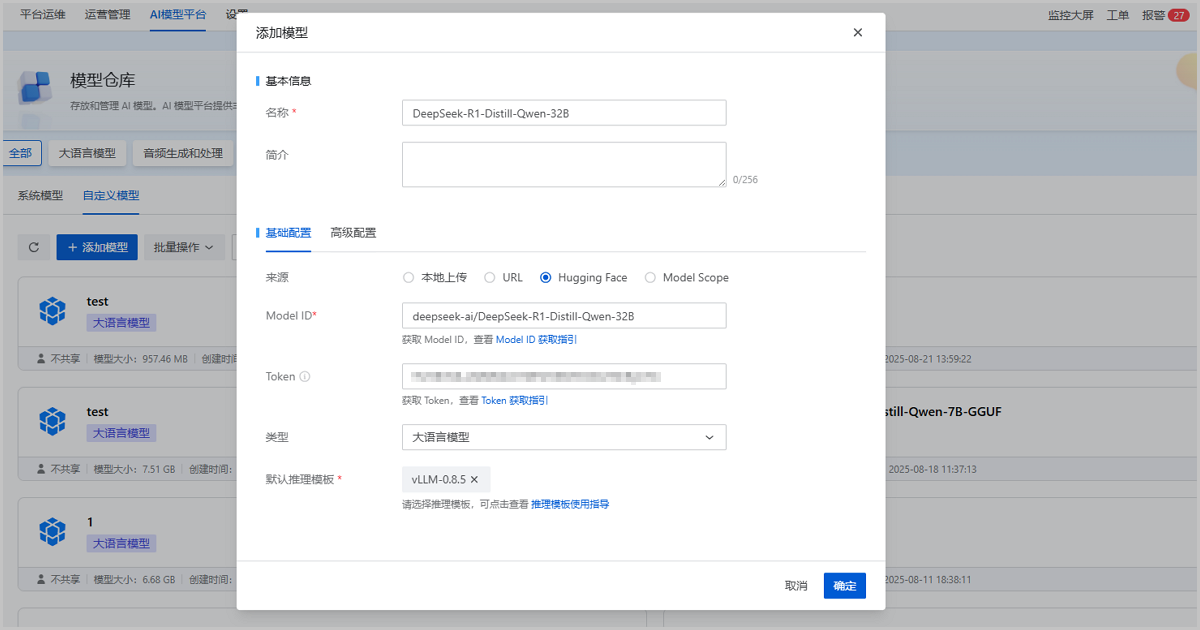
图1 添加自定义模型 -
创建推理服务
在自定义模型界面,找到并点击上一步添加的模型,在右侧详情页,点击创建推理服务,弹出创建推理服务界面,可参考以下示例输入相应内容:
- 基本信息
- 部署名称:设置推理服务名称
- 简介:可选项,可留空不填
- 模型:显示当前模型名称
- 模型类型:显示当前模型类型
- 选择推理模板:使用默认推理模板,即vLLM-0.8.5
- 实例配置
- 部署方式:本场景选择云主机部署
- 最小部署单元:设置部署的云主机数量,本场景部署4台说明: 云主机数量必须是2的N次方。
- CPU架构:选择云主机CPU架构,本场景选择x86_64架构
- 高级选型:可选项,指定云主机所在集群、主存储、IP地址。本场景不指定,由系统自动分配
- 云主机镜像:使用推理模板中的默认镜像
- GPU:勾选使用GPU
- 每台GPU配置:选择GPU厂商、型号,及每台云主机加载的GPU数量,本场景设置为4个说明: GPU数量必须是2的N次方。
- CPU和内存:设置云主机CPU和内存
- 服务配置:设置推理服务端口、最大并发数、启动超时时间等参数,本场景使用默认值
设置完成后,点击确定,开始创建推理服务。如图2所示: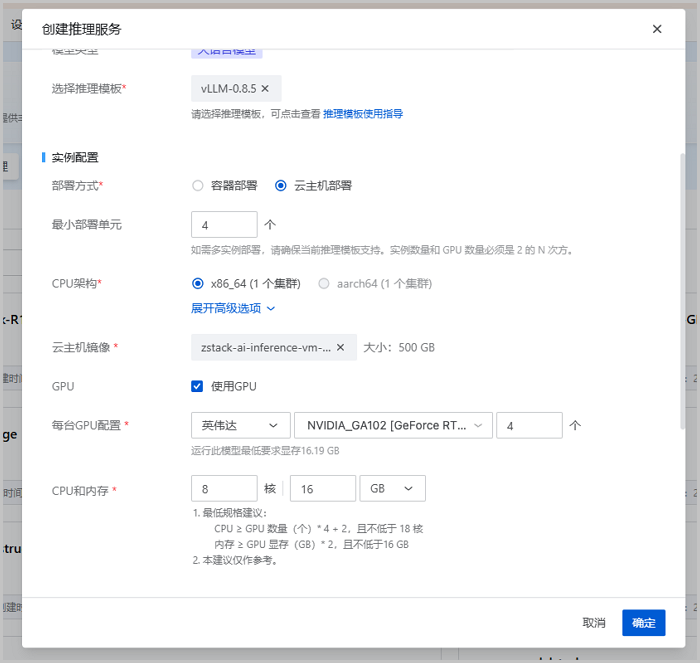
图2 创建推理服务 - 基本信息