dGPU基于CUDA API拦截转发技术,按需切分物理GPU显存,动态分配给不同云主机使用。借助该技术,多个服务可共享同一张物理GPU卡,大幅提升GPU利用率,降低AI算力成本。
本场景假定用户需基于系统模型DeepSeek-R1-Distill-Qwen-7B部署推理服务。当前物理机上装有一张NVIDIA GPU卡
(总显存:24GB) ,需供多个业务使用,无法被该推理服务独占。用户通过dGPU模式,申请其中12GB显存用于独立运行该推理服务,同时保证其他业务不受影响。
说明: 使用本功能,需确保:
- 提前购买dGPU算力切分许可证。
- 物理机使用x86_64操作系统。
- 准备NVIDIA GPU驱动 (570.x或以上版本) 、CUDA (12.1或以上版本) 。
- 用于部署推理服务的云主机使用Linux操作系统,并安装性能优化工具。
本节以上述场景为例,详细介绍使用dGPU创建推理服务的方法,主要包括以下步骤:
- 准备物理GPU设备
- 为物理GPU启用dGPU模式
- 创建推理服务
- 进入推理服务
-
准备物理GPU设备
-
在物理机详情页开启IOMMU
登录ZStack AIOS UI界面,点击,选择目标物理机,点击进入其详情页。在物理机详情页开启IOMMU启用状态,并确认IOMMU就绪状态为可用。如图1所示:
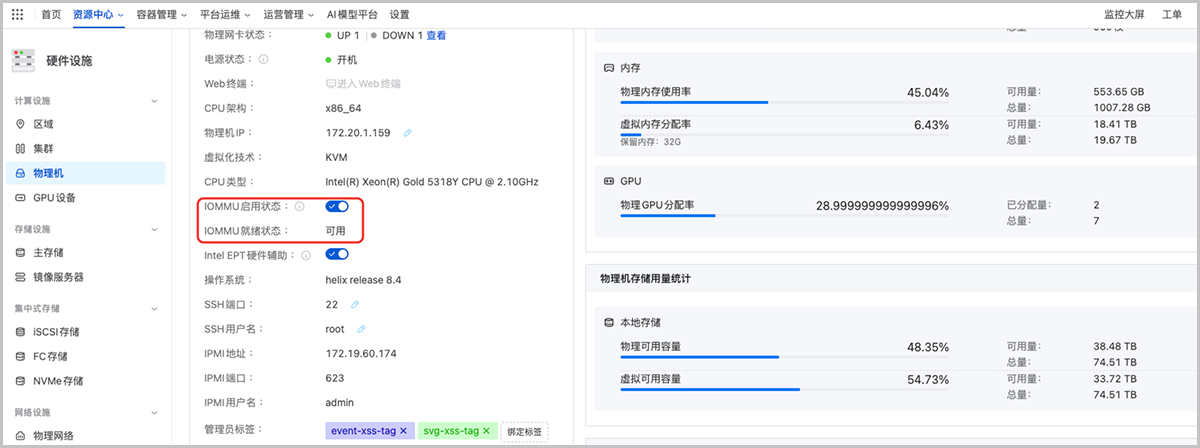
图1 开启物理机IOMMU
-
在物理机详情页开启IOMMU
-
为物理GPU启用dGPU模式
说明:
- 启用dGPU模式后,该物理GPU设备无法使用透传、vGPU功能;正在用于透传或vGPU的物理GPU设备无法启用dGPU模式。
- 如一台物理机上安装多个物理GPU设备,所有物理GPU设备必须同步开启/停用dGPU模式。如有物理GPU已透传给云主机使用,需先从云主机卸载。
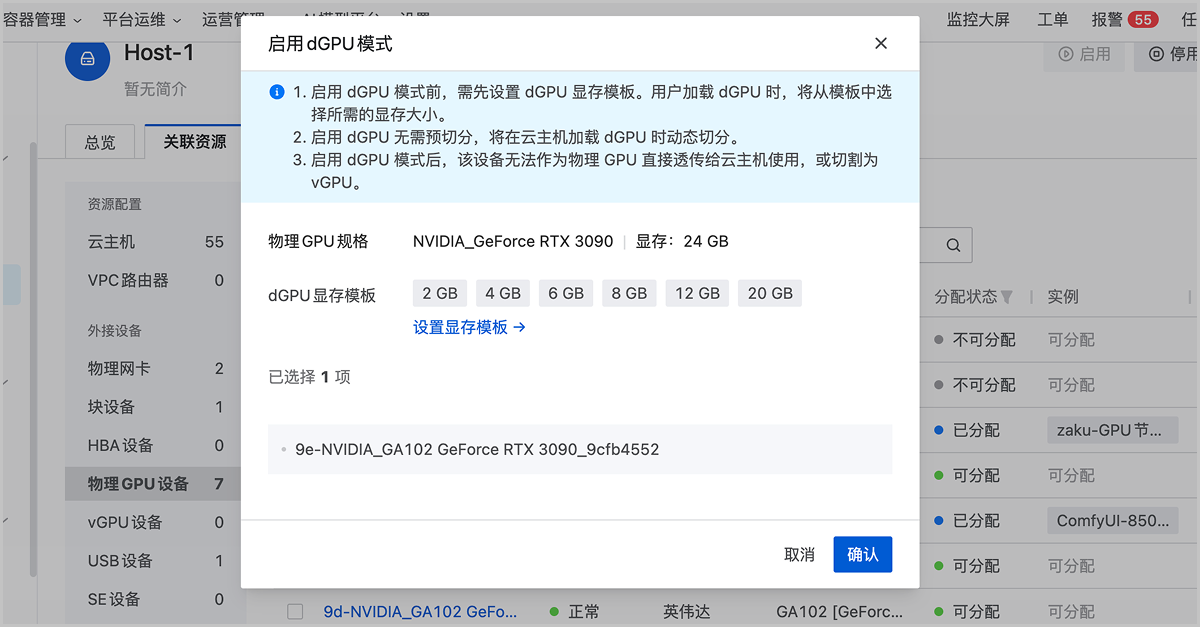
在物理机详情页,点击。在物理GPU设备列表,选择目标物理GPU,点击。可参考以下示例进行参数设置:- 物理GPU规格:显示当前GPU设备对应的规格信息
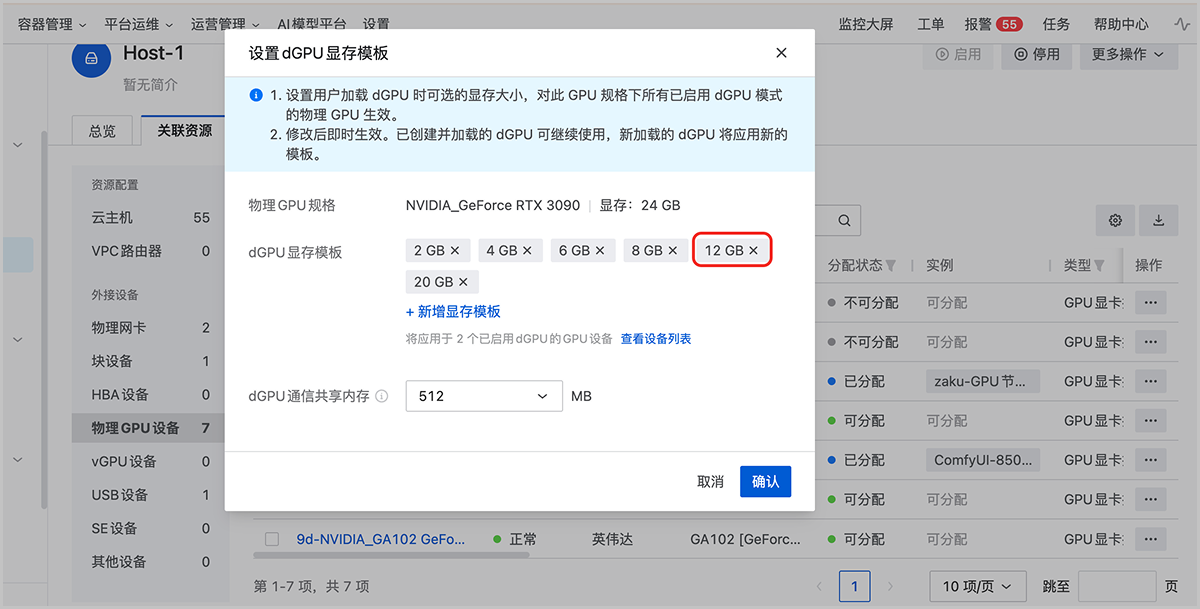
- dGPU显存模板:显示当前GPU规格已设置的dGPU显存模板,用户可点击设置显存模板,跳转到设置dGPU显存模板界面,调整以下参数:
- dGPU显存模板:设置使用该GPU进行dGPU算力切分时,云主机可调度的显存大小,可添加多个显存模板。本场景中,确保已添加12GB的显存模板,供后续推理服务使用
- dGPU通信共享内存:在物理机上创建 dGPU 的专属底层高速通信设备。常规场景下可设置为256MB,高吞吐业务场景可适量调大,本场景设置为512MB
显存模板和dGPU模式均设置完成后,点击确定。
至此,使用dGPU的推理服务已创建完成。物理GPU的剩余显存仍可以dGPU形式分配给其他云主机使用。用户可在列表,持续关注dGPU状态和使用情况。