- 物理机安装GPU驱动、vGPU驱动。
- 物理机启用IOMMU设置。
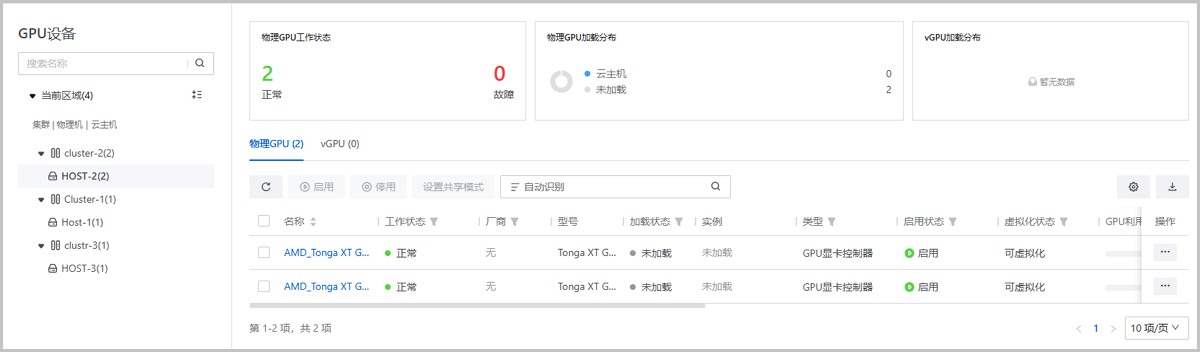
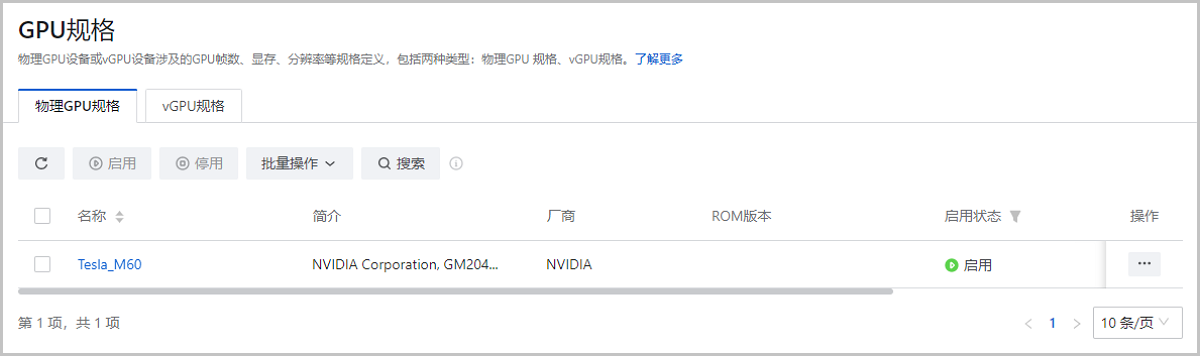
- 查看物理GPU/物理GPU规格。
- 虚拟化切割。
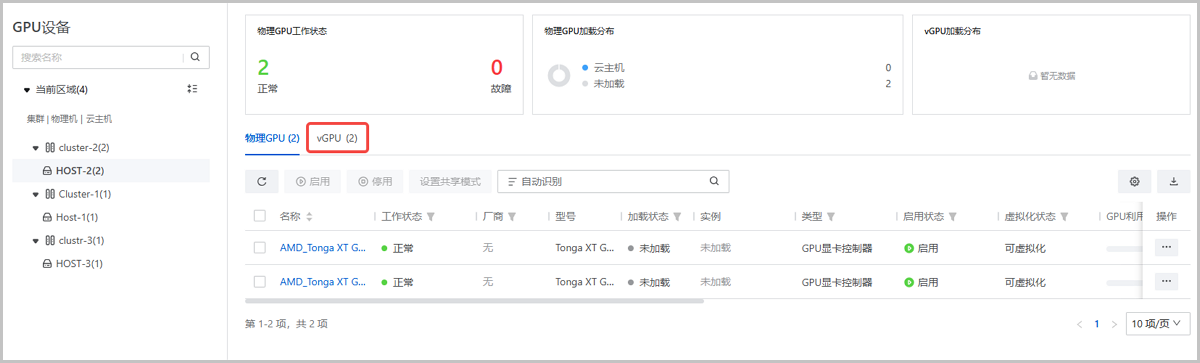
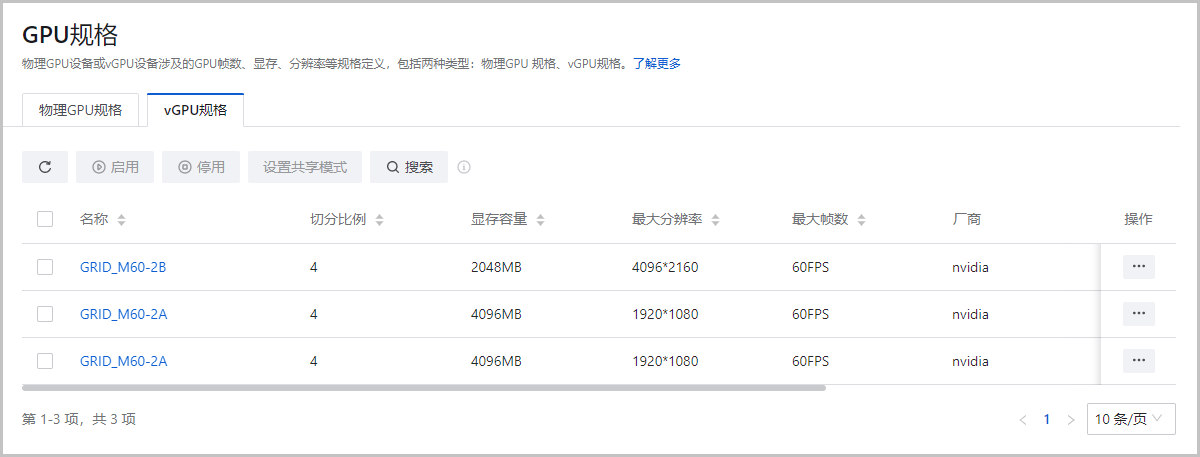
- 查看vGPU/vGPU规格。
- 云主机加载vGPU。
- 云主机安装vGPU驱动。
- 创建vGPU设备报警器 (可选)。
- 查看vGPU设备监控,并在异常时接收报警通知 (可选)。
使用vGPU虚拟化功能前,请务必确保所有准备工作已完成且准确无误。以下详细介绍vGPU虚拟化功能的操作步骤:
-
物理机启用IOMMU设置
确保物理机BIOS已开启Intel VT-d / AMD IOMMU配置的前提下,在ZStack Cloud云平台开启物理机IOMMU设置。
- 新添加物理机:在界面添加物理机过程,选择扫描物理机IOMMU设置配置,添加物理机的同时开启IOMMU设置。如图1所示:
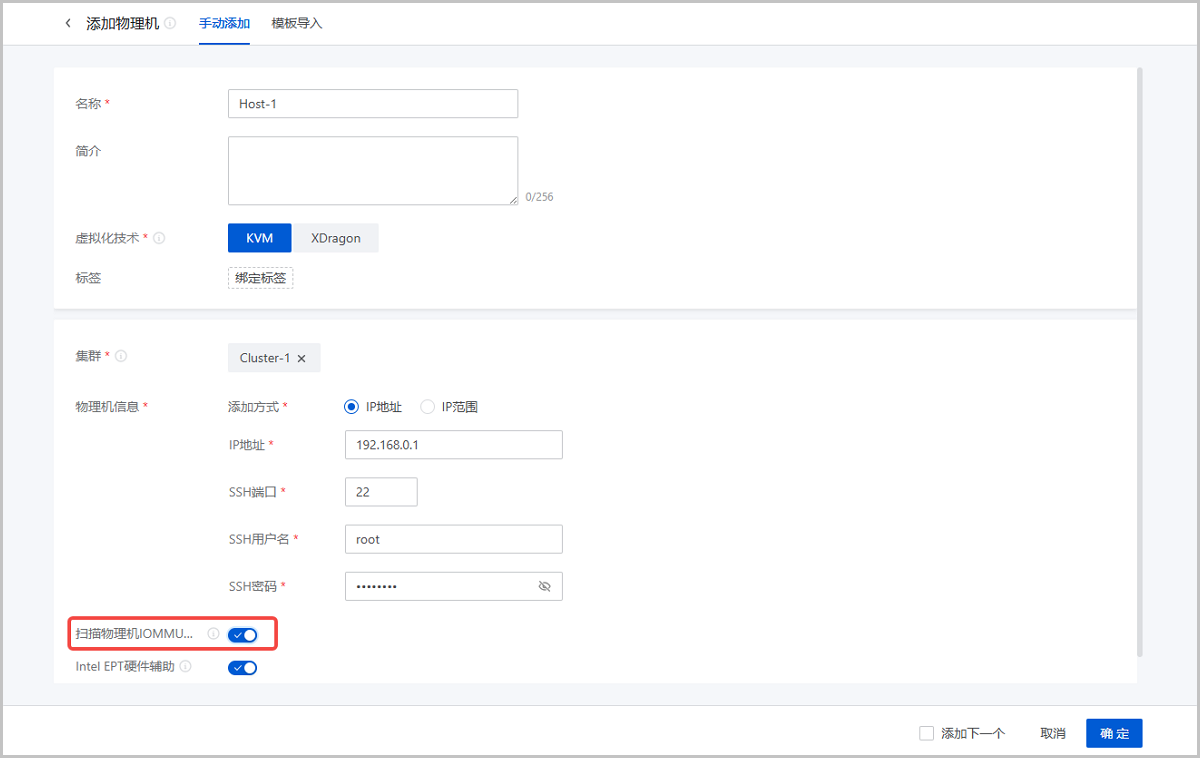
图1 新添加物理机并启用IOMMU设置 - 已添加物理机:在物理机详情页,启用IOMMU启用状态配置,针对已添加物理机开启IOMMU设置,重启物理机生效。如图2所示:
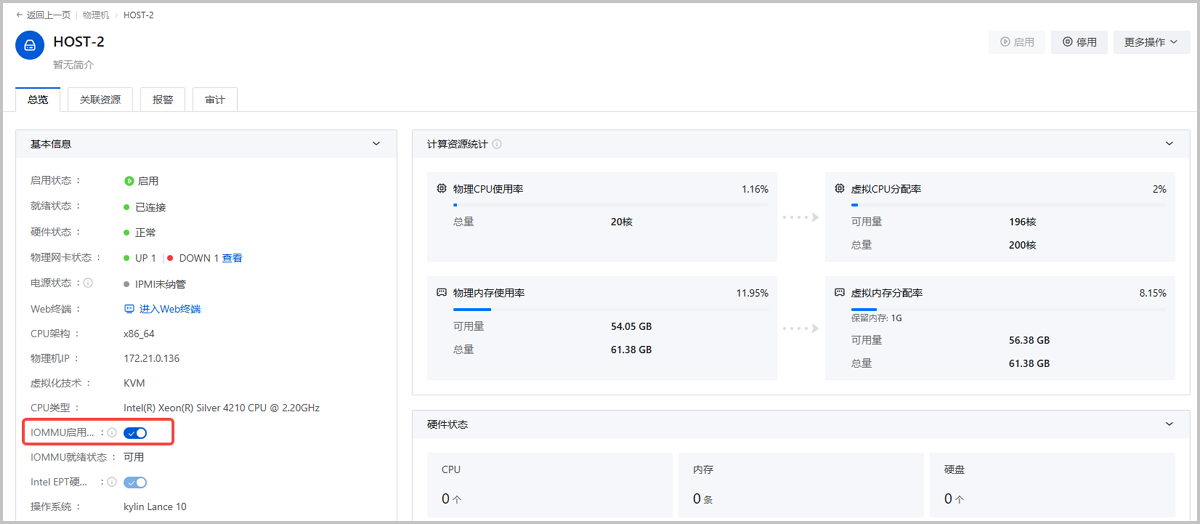
图2 已添加物理机启用IOMMU设置
说明: 物理机开启IOMMU设置后,还需在物理机详情页确保IOMMU就绪状态为可用,否则也无法正常使用vGPU功能。若IOMMU启用状态为启用,但IOMMU就绪状态不可用,可能存在以下原因:- 开启IOMMU设置但未重启物理机,手动重启物理机即可。
- 物理机配置错误,请进入物理机BIOS并开启Intel VT-d / AMD IOMMU配置。
- 新添加物理机:在界面添加物理机过程,选择扫描物理机IOMMU设置配置,添加物理机的同时开启IOMMU设置。
- 查看物理GPU/物理GPU规格
-
虚拟化切割
虚拟化切割即表示将未用于透传的物理GPU经过虚拟化,切割成若干固定规格的vGPU。不同厂商的物理GPU虚拟化切割方法略有不同,ZStack Cloud目前支持虚拟化切割NVIDIA物理GPU和AMD物理GPU。
- 虚拟化切割NVIDIA物理GPU:支持按照所选切割规格,单独虚拟化切割NVIDIA物理GPU。
方法一:在物理机详情页,点击,选择未加载云主机、可虚拟化的物理GPU设备,点击,按所选规格虚拟化切割NVIDIA物理GPU。
方法二:在ZStack Cloud主菜单,点击,进入GPU设备页面,选择未加载云主机、可虚拟化的物理GPU设备,点击,按所选规格虚拟化切割NVIDIA物理GPU。
如图5所示: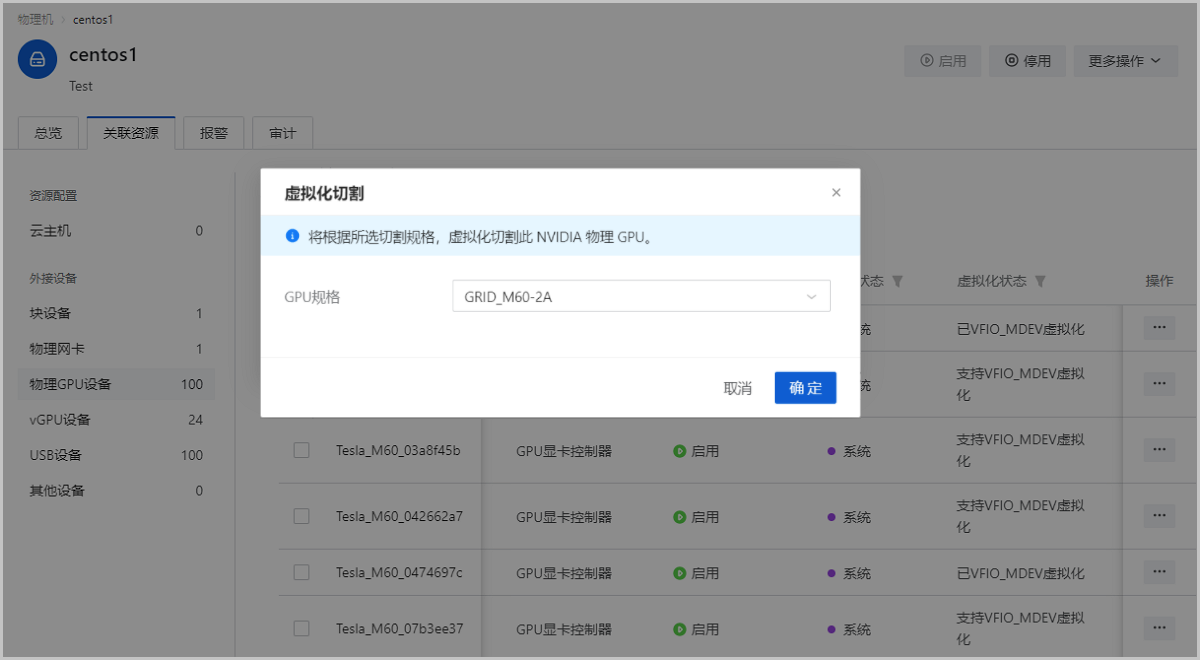
图5 虚拟化切割NVIDIA物理GPU 切割规格显示此物理GPU可被切割的所有规格列表。例如:GRID M60-2A(4ins-2048 MiB-1280*1024)表示将一个核心的物理GPU虚拟化切割成4个帧数为60FPS、显存为2048MB、分辨率为1280*1024的vGPU。说明: 若需要将vGPU还原成物理GPU,请点击按钮执行操作。虚拟化还原NVIDIA vGPU需确保此物理GPU相关的vGPU已经全部从云主机卸载。 - 虚拟化切割AMD物理GPU:支持按照所选切割数量,同时虚拟化切割当前AMD显卡对应的所有物理GPU,执行虚拟化切割的操作路径和NVIDIA物理GPU相同。如图6所示:
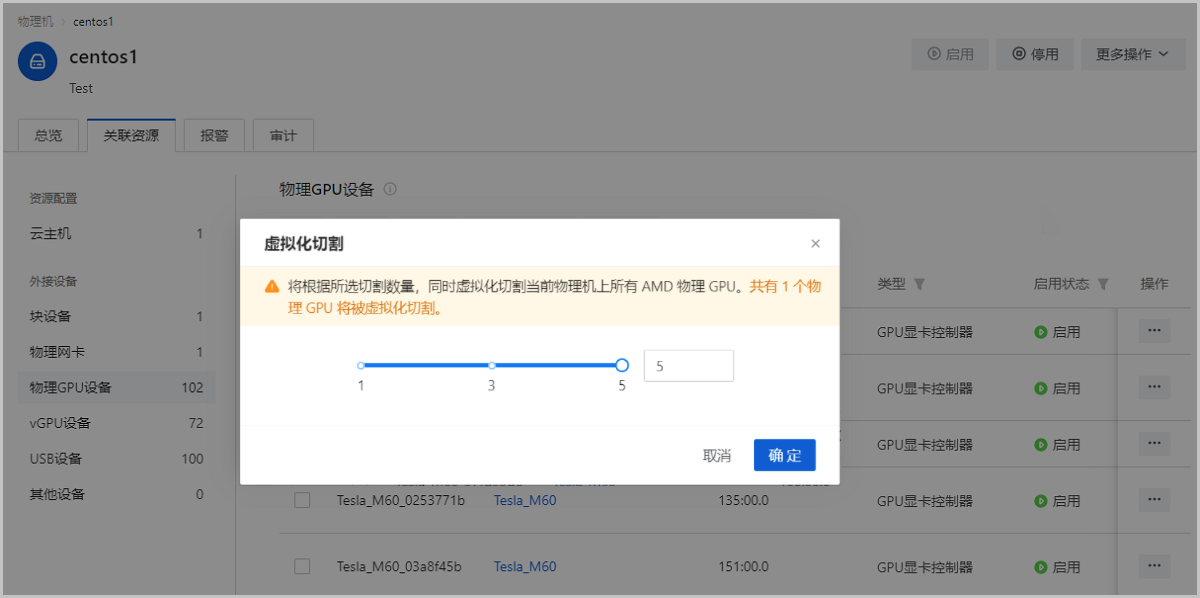
图6 虚拟化切割AMD物理GPU 说明: 若需要将vGPU还原成物理GPU,请点击按钮执行操作。虚拟化还原AMD vGPU需确保当前AMD显卡对应的所有AMD vGPU全部已经从云主机卸载。
- 虚拟化切割NVIDIA物理GPU:支持按照所选切割规格,单独虚拟化切割NVIDIA物理GPU。
- 查看vGPU/vGPU规格
-
云主机加载vGPU
ZStack Cloud云平台支持以下几种方法为云主机加载vGPU:
- 方法一:创建云主机并加载vGPU在界面创建云主机过程,基础参数配置完成后在高级选项中加载物理GPU,支持指定规格和指定设备两种加载方法。可参考以下示例输入相应内容:
- 加载规格:创建云主机时指定vGPU规格,通过规格自动分配GPU设备。支持关机自动卸载设备功能(默认勾选),若勾选表示云主机关机后自动卸载GPU设备,下次重启后根据GPU规格重新分配新的GPU设备;若不勾选表示云主机关机后保留已加载的GPU设备,下次重启后继续使用原来的GPU设备。如图9所示:
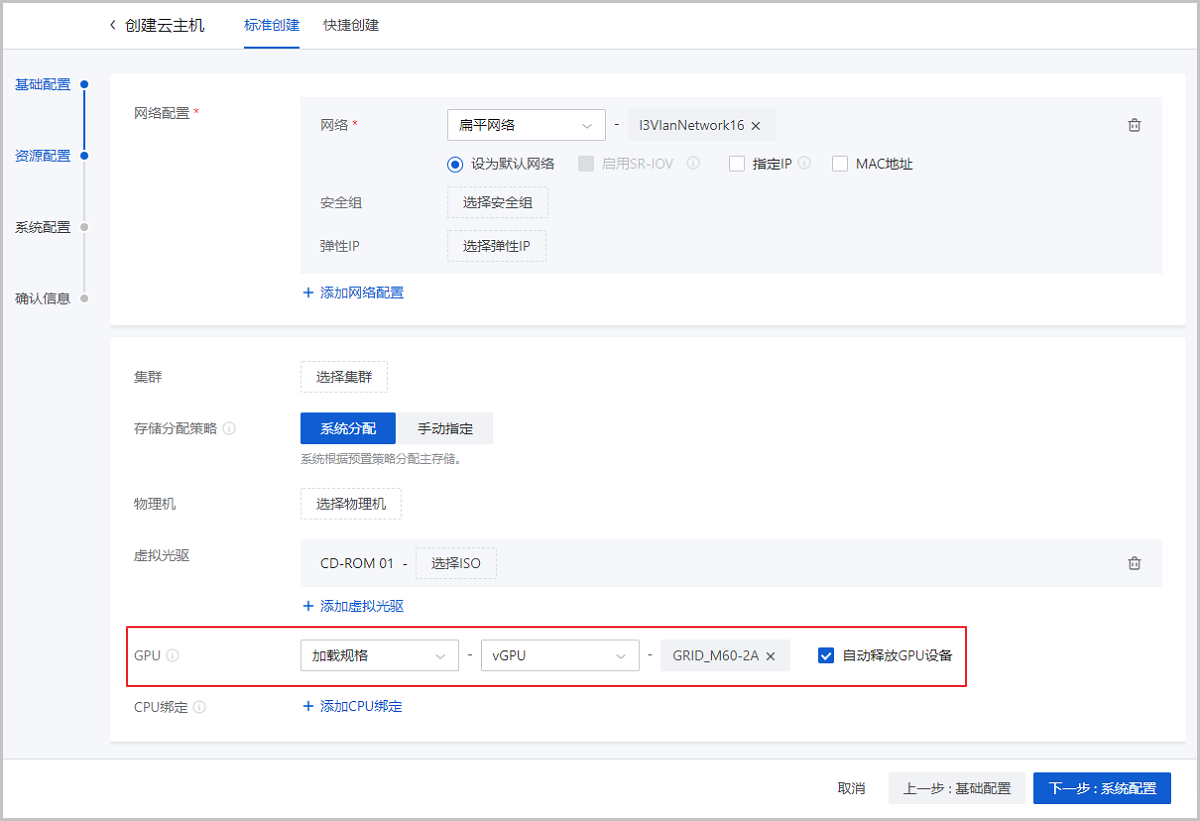
图9 加载规格 - 加载设备:创建云主机时指定固定的vGPU设备,为云主机加载所选GPU设备。如图10所示:
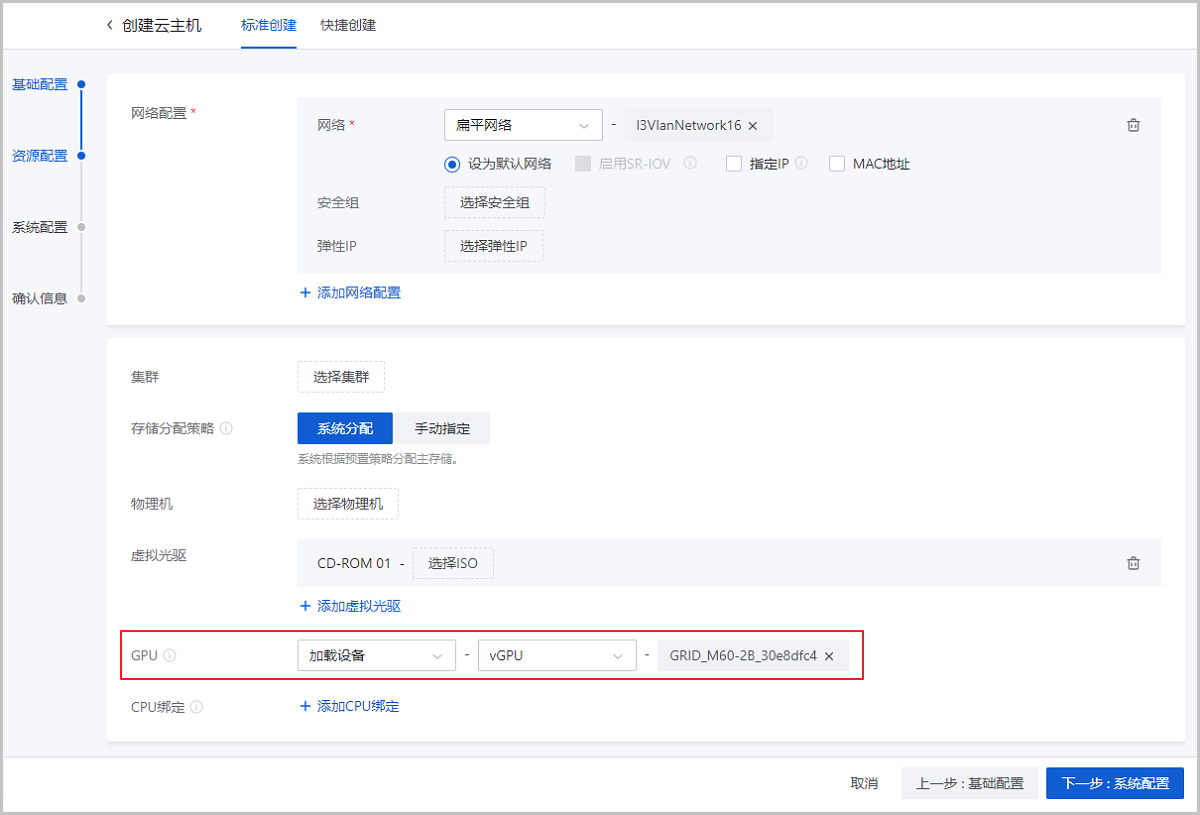
图10 加载设备
- 加载规格:创建云主机时指定vGPU规格,通过规格自动分配GPU设备。支持关机自动卸载设备功能(默认勾选),若勾选表示云主机关机后自动卸载GPU设备,下次重启后根据GPU规格重新分配新的GPU设备;若不勾选表示云主机关机后保留已加载的GPU设备,下次重启后继续使用原来的GPU设备。
- 方法二:单个已有云主机加载vGPU
在ZStack Cloud主菜单,点击,进入云主机界面,点击云主机名称,进入云主机界面的配置信息子页面的vGPU设备栏,点击加载按钮手动加载vGPU。
如图11所示: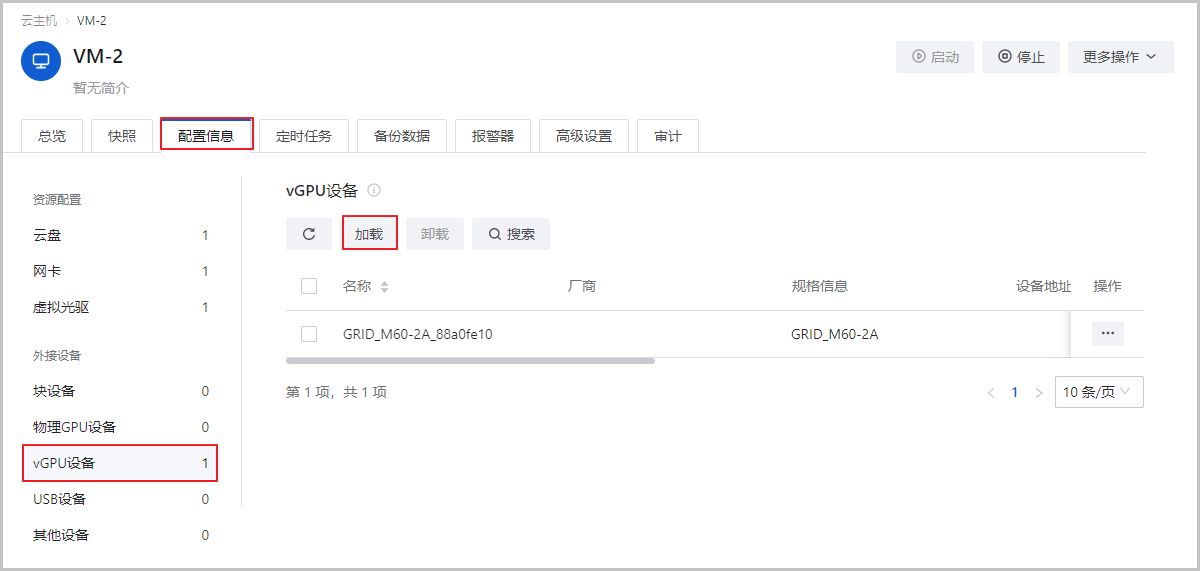
图11 加载vGPU - 一台云主机支持同时加载一个vGPU,暂不支持将物理GPU和vGPU同时加载到同一台云主机使用。
- 若需要释放GPU设备,选中GPU设备,点击按钮,释放GPU设备。
- 执行加载、卸载vGPU操作前,请确保云主机状态为已停止。
- 方法三:批量为已有云主机设置vGPU
在云主机管理界面选择一台或多台云主机,点击按钮,批量为云主机加载vGPU设备或vGPU规格。
如图12所示: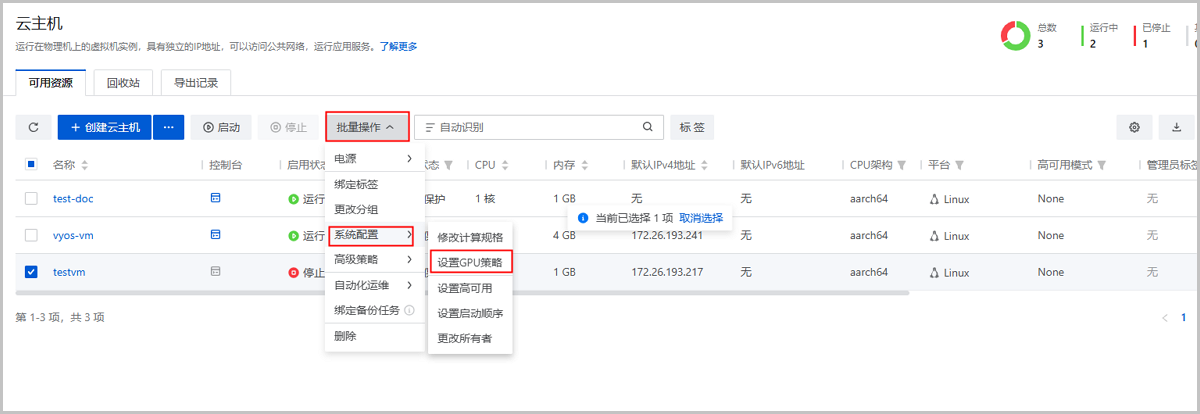
图12 批量加载GPU规格
- 方法一:创建云主机并加载vGPU
-
云主机安装vGPU驱动
云主机加载vGPU后,需要安装对应的驱动程序才能正常使用。不同vGPU的驱动以及安装方法可能不同,详情请联系GPU设备提供厂商获取帮助。本章节以Linux云主机安装NVIDIA vGPU驱动为例介绍参考操作流程:
- 获取驱动安装相关文件:
获取GPU设备匹配的显卡驱动和CUDA toolkit文件。
- 禁用nouveau驱动:NVIDIA显卡的官方驱动和系统自带的nouveau驱动存在冲突。执行
lsmod | grep nouveau命令,若有输出内容表示存在nouveau驱动,可参考以下方法禁用nouveau驱动;若不存在nouveau驱动,跳过此步骤即可。# touch /etc/modprobe.d/nvidia-installer-disable-nouveau.conf #创建文件,将以下两行内容保存至文件中 blacklist nouveau options nouveau modeset=0 - 安装gcc、kernel-devel、kernel-headers:依次执行以下命令,安装gcc、与内核版本一致的kernel-devel和kernel-headers。建议使用相同版本的ISO配置本地源安装。
# yum install gcc kernel-devel-$(uname -r) kernel-headers-$(uname -r) #重构 initramfs 镜像 # cp /boot/initramfs-$(uname -r).img /boot/initramfs-$(uname -r).img.bak # dracut /boot/initramfs-$(uname -r).img $(uname -r) --force #只使用文本模式重启云主机 # systemctl set-default multi-user.target # init 3 # reboot # lsmod | grep nouveau #云主机重新启动后,检查nouveau驱动应该没有被使用 - 安装NVIDIA
驱动:将下载的驱动包拷贝至云主机系统内,依次执行以下命令运行驱动文件:
命令执行后将开始解压驱动包并进入安装步骤,安装过程可能出现一些警告,依次确认即可,不影响驱动安装。若出现error报错,请参考表1检查环境。# chmod +x NVIDIA-Linux-x86_64-346.47.run #配置可执行权限 # ./NVIDIA-Linux-x86_64-346.47.run #运行驱动文件表1 报错处理 报错 解决方案 ERROR: Unable to find the kernel source tree for the currently running kernel. Please make sure you have installed the kernel source files for your kernel and that they are properly configured; on Red Hat Linux systems, for example, be sure you have the 'kernel-source' or 'kernel-devel' RPM installed. If you know the correct kernel source files are installed, you may specify the kernel source path with the '--kernel-source-path' command line option.
需要确保kernel、kernel-headers、kernel-devel是否均已安装,并且版本号完全一致 ERROR: The Nouveau kernel driver is currently in use by your system. This driver is incompatible with the NVIDIA driver, and must be disabled before proceeding. Please consult the ow to correctly disable the Nouveau kernel driver.
需要禁用nouveau驱动 ERROR: Failed to find dkms on the system!
ERROR: Failed to install the kernel module through DKMS. No kernel module was installed; please try installing again without DKMS, or check the DKMS logs for more information.
需要安装DKMS,它可以帮我们维护内核外的驱动程序,在内核版本变动之后可以自动重新生成新的模块 ERROR: Unable to load the kernel module 'nvidia.ko'. This happens most frequently when this kernel module was built against the wrong or improperly configured kernel sources, with a version of gcc that differs from the one used to build the target kernel, or if a driver such as rivafb, nvidiafb, or nouveau is present and prevents the NVIDIA kernel module from obtaining ownership of the NVIDIA graphics device(s), or no NVIDIA GPU installed in this system is supported by this NVIDIA Linux graphics driver release.
执行命令 ./NVIDIA-Linux-x86_64-384.98.run --kernel-source-path=/usr/src/kernels/3.10.0-XXX.x86_64/ -k $(uname -r)即可 - 检查驱动安装情况:分别执行以下两条命令,检查驱动安装情况。若返回结果能够显示显卡的型号信息,说明驱动已经安装成功。
# lspci |grep NVIDIA # nvidia-smi - 安装CUDA
toolkit:将下载的驱动包拷贝至云主机系统内,依次执行以下命令执行驱动文件:
# chmod +x cuda_8.0.61_375.26_linux.run #配置可执行权限 # ./cuda_8.0.61_375.26_linux.run #运行驱动文件安装过程需要配置一些参数,请参考下图进行配置。
如图13所示: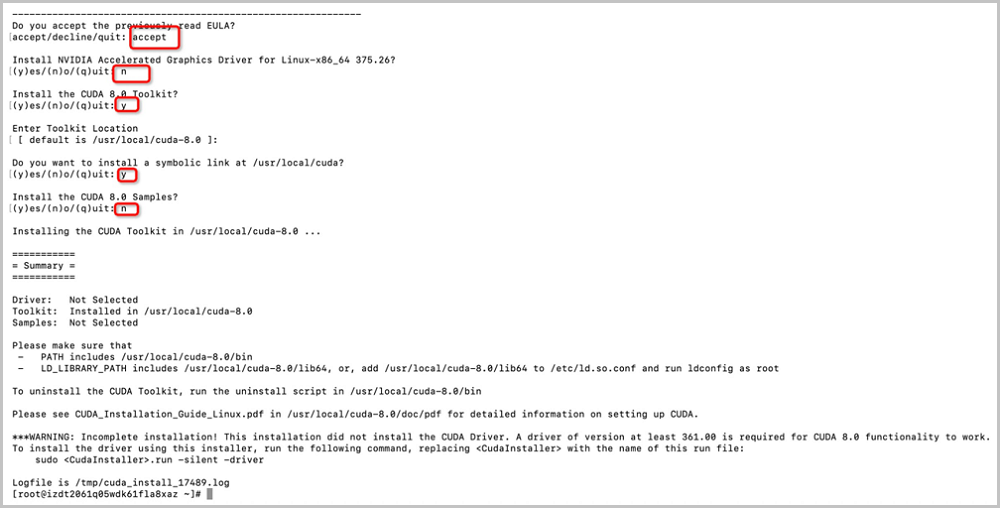
图13 安装CUDA toolkit - 配置环境变量:执行
vim /root/.bashrc命令,将以下内容保存至此文件,完成环境变量配置:#gpu driver export CUDA_HOME=/usr/local/cuda-8.0 export PATH=/usr/local/cuda-8.0/bin:$PATH export LD_LIBRARY_PATH=/usr/local/cuda-8.0/lib64:$LD_LIBRARY_PATH export LD_LIBRARY_PATH="/usr/local/cuda-8.0/lib:${LD_LIBRARY_PATH}"环境变量添加完成后立即生效,可执行以下命令进行验证测试:# source ~/.bashrc # cd /usr/local/cuda-8.0/samples/1_Utilities/deviceQuery # make # ./deviceQuery
- 获取驱动安装相关文件: